The Map interface in Java is a part of the java.util package and provides a way to store key-value pairs. It does not inherit from Collection, and instead defines a specific set of methods to interact with the key-value mappings.
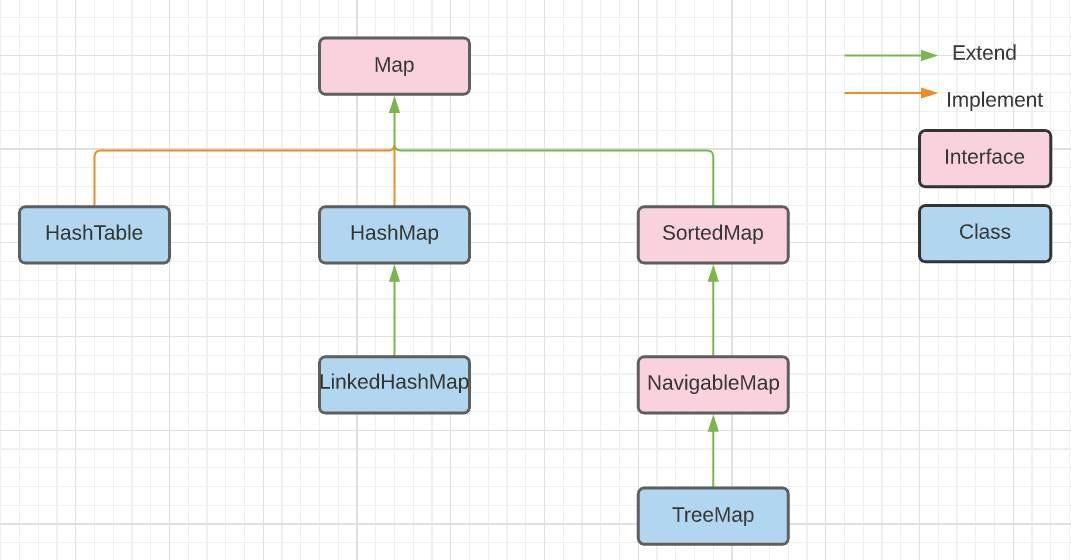
The Map interface in Java is a part of the java.util package and provides a way to store key-value pairs. It does not inherit from Collection, and instead defines a specific set of methods to interact with the key-value mappings.
Map Interface:Here is a list of all the methods from the Map interface with their corresponding use cases:
void clear()boolean containsKey(Object key)boolean containsValue(Object value)Set<Map.Entry<K, V>> entrySet()V get(Object key)boolean isEmpty()Set<K> keySet()V put(K key, V value)void putAll(Map<? extends K, ? extends V> m)V remove(Object key)int size()Collection<V> values()
Map is Needed:A Map in Java is an interface that represents a collection of key-value pairs. It is needed in scenarios where you need to:
Map suitable for situations where fast lookups, inserts, and deletions are required, such as searching through databases, caches, and directories.Map implementations (like HashMap, TreeMap, LinkedHashMap, etc.) provide various features like ordering of keys, sorted order, or maintaining insertion order, making Map a versatile choice for different use cases.Map can be viewed as an associative array or a dictionary that lets you associate values with keys for easier access.package com.niteshsynergy.map;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
import java.util.Collection;
import java.util.Map.Entry;
public class MapExample {
public static void main(String[] args) {
// Create a new HashMap
Map<String, Integer> map = new HashMap<>();
// Add entries to the map
map.put("Apple", 10);
map.put("Banana", 20);
map.put("Orange", 30);
// 1. Using get() to retrieve a value by key
Integer appleValue = map.get("Apple");
System.out.println("Apple: " + appleValue); // Output: Apple: 10
// 2. Using keySet() to iterate over keys and retrieve values
System.out.println("\nUsing keySet():");
Set<String> keys = map.keySet();
for (String key : keys) {
System.out.println(key + ": " + map.get(key));
}
// Output:
// Apple: 10
// Banana: 20
// Orange: 30
// 3. Using values() to iterate over values
System.out.println("\nUsing values():");
Collection<Integer> values = map.values();
for (Integer value : values) {
System.out.println(value);
}
// Output:
// 10
// 20
// 30
// 4. Using entrySet() to iterate over key-value pairs
System.out.println("\nUsing entrySet():");
Set<Entry<String, Integer>> entries = map.entrySet();
for (Entry<String, Integer> entry : entries) {
System.out.println(entry.getKey() + ": " + entry.getValue());
}
// Output:
// Apple: 10
// Banana: 20
// Orange: 30
// 5. Using forEach() with lambda
System.out.println("\nUsing forEach():");
map.forEach((key, value) -> System.out.println(key + ": " + value));
// Output:
// Apple: 10
// Banana: 20
// Orange: 30
// 6. Using computeIfAbsent() to add a value if the key doesn't exist
Integer valueForMango = map.computeIfAbsent("Mango", key -> 40);
System.out.println("\nUsing computeIfAbsent():");
System.out.println("Mango: " + valueForMango); // Output: Mango: 40
// 7. Using getOrDefault() to retrieve a value or a default value
Integer valueForGrapes = map.getOrDefault("Grapes", 50);
System.out.println("\nUsing getOrDefault():");
System.out.println("Grapes: " + valueForGrapes); // Output: Grapes: 50
// 8. Using remove() to delete an entry
Integer removedValue = map.remove("Apple");
System.out.println("\nUsing remove():");
System.out.println("Removed Apple: " + removedValue); // Output: Removed Apple: 10
}
}

A HashMap in Java is a part of the java.util package and is one of the most commonly used collections for storing key-value pairs.
It is backed by an array of buckets (also known as an array of entries), and uses hashing to locate where each entry should go.
Here’s a step-by-step breakdown of how HashMap works internally:
package com.niteshsynergy.map;
import java.util.HashMap;
public class Demo03HashMap {
public static void main(String[] args) {
// Create a HashMap with initial capacity of 4 and load factor of 0.75
HashMap<String, Integer> map = new HashMap<>(4, 0.75f);
// Adding key-value pairs to the HashMap
map.put("Apple", 10);
map.put("Banana", 20);
map.put("Cherry", 30);
map.put("Date", 40);
map.put("Elderberry", 50); // This triggers resizing
// Accessing values using get()
System.out.println("Apple: " + map.get("Apple"));
System.out.println("Banana: " + map.get("Banana"));
System.out.println("Cherry: " + map.get("Cherry"));
System.out.println("Date: " + map.get("Date"));
System.out.println("Elderberry: " + map.get("Elderberry"));
// Removing an entry
map.remove("Banana");
System.out.println("After removing Banana: " + map);
}
}
HashMap is initialized with an initial capacity of 4. It means that it will start with 4 buckets."Apple" -> 10:hashCode() for "Apple" is computed.hashCode("Apple") % 4 determines the bucket where this key-value pair will go."Apple" -> 10 is inserted there."Banana" -> 20:hashCode() for "Banana" is computed.hashCode("Banana") % 4 determines the bucket index."Banana" -> 20 is inserted into bucket 3."Cherry" -> 30:hashCode() for "Cherry" is computed.hashCode("Cherry") % 4 determines the bucket index."Cherry" -> 30 is inserted into an available bucket."Date" -> 40:hashCode() for "Date" is computed.hashCode("Date") % 4 determines the bucket index."Date" -> 40 is inserted into a bucket."Elderberry" -> 50:HashMap exceeds the load factor threshold (0.75 * 4 = 3).HashMap is doubled from 4 to 8. This means the bucket array size increases to accommodate more entries.get() Method)map.get("Apple"): The hash value for "Apple" is calculated, and the bucket index is derived. The key "Apple" is found in the corresponding bucket, and its value 10 is returned.map.get("Banana"): The hash value for "Banana" is calculated, and it’s found in the corresponding bucket. The value 20 is returned.map.get("Cherry"): Similarly, "Cherry" is retrieved, returning the value 30.map.get("Date"): The key "Date" is hashed, and the value 40 is returned.map.get("Elderberry"): The key "Elderberry" is hashed, and its value 50 is returned.
remove() Method)map.remove("Banana"): The key "Banana" is hashed, and its bucket is located. The key-value pair is removed from the map, and the updated map is printed.
In this example, let’s assume that "Apple", "Banana", "Cherry", "Date", and "Elderberry" all have different hash values (or hash values that map to different buckets), so no collisions occurred.
However, if there were collisions (i.e., two or more keys hashed to the same bucket), HashMap would handle them as follows:
As soon as the number of entries in the HashMap exceeds 3 (because 0.75 * 4 = 3), the HashMap will resize. This resizing involves:
HashMapA HashMap in Java is part of the java.util package and is used to store key-value pairs. It uses a hash table to store the data. Here's how it works:
HashMap uses a linked list or a tree (for larger buckets) to store multiple entries at the same index.HashMap is 16. This means it will create an internal array of 16 buckets.HashMap will resize (double the capacity).When you add a key-value pair into the HashMap, the key is hashed, and the hash code is used to determine the index where the value will be stored in the internal array.
For example:
Emp emp1 = new Emp(101, "Nitesh");
Emp emp2 = new Emp(102, "Ajay");
Both of these Emp objects will go through the hashing process:
hashCode() method is called on the key (emp1.getId(), emp2.getId()), and a hash value is generated.hashCode % capacity (capacity is 16 by default).Collisions occur when two keys have the same hash code (or the same bucket index). In this case, both values will be stored in a linked list or a balanced tree within the same bucket.
Let’s say we have two objects, emp1 and emp2, that both hash to the same bucket index. In this case, both emp1 and emp2 will be stored in the same bucket, and they will be added in a linked list or a tree structure.
Here’s an example of HashMap with potential collisions, and how to add and retrieve values:
import java.util.HashMap;
import java.util.Map;
class Emp {
int id;
String name;
Emp(int id, String name) {
this.id = id;
this.name = name;
}
// Override hashCode() to create a scenario for collision
@Override
public int hashCode() {
return id % 16; // This forces a collision for id 1 and 17 (same hash code)
}
// Override equals() to check equality of Emp objects by id
@Override
public boolean equals(Object obj) {
if (this == obj) return true;
if (obj == null || getClass() != obj.getClass()) return false;
Emp emp = (Emp) obj;
return id == emp.id;
}
@Override
public String toString() {
return "Emp{id=" + id + ", name='" + name + "'}";
}
}
public class HashMapExample {
public static void main(String[] args) {
Map<Emp, String> empMap = new HashMap<>();
// Adding entries to the HashMap
Emp emp1 = new Emp(1, "Nitesh");
Emp emp2 = new Emp(17, "Ajay"); // Same hashCode as emp1
Emp emp3 = new Emp(2, "Ravi");
empMap.put(emp1, "Employee 1");
empMap.put(emp2, "Employee 17");
empMap.put(emp3, "Employee 2");
// Retrieving the values
System.out.println(empMap.get(emp1)); // Should print "Employee 1"
System.out.println(empMap.get(emp2)); // Should print "Employee 17"
System.out.println(empMap.get(emp3)); // Should print "Employee 2"
}
}
Emp Class:hashCode() method to make sure that Emp objects with ids 1 and 17 will hash to the same value (collision).equals() method to ensure that two Emp objects with the same id are considered equal, which is necessary for HashMap to retrieve the correct value during lookup.HashMap Behavior:emp1 and emp2 are added to the HashMap, both will hash to the same index (since their hashCode() values are the same). Therefore, a collision occurs, and the HashMap stores both emp1 and emp2 in the same bucket.HashMap uses a linked list or tree (depending on the number of elements in the bucket) to store multiple elements at the same bucket index.empMap.get(emp1) or empMap.get(emp2), the HashMap checks the hash code, finds the correct bucket, and then uses the equals() method to match the correct entry.emp1 and emp2 are at the same index, the equals() method ensures that the right Emp object is returned.hashCode() function that distributes the hash codes more evenly across the buckets. This minimizes the likelihood of collisions.HashMap: As the HashMap grows (over 75% full), it will automatically resize and rehash the entries, reducing the chances of collisions.Tree-based Buckets: If a collision occurs in a bucket with a large number of elements, Java will use a balanced tree (since Java 8) to improve retrieval time from O(n) to O(log n).
Emp Class and HashMap Implementation: Read thisimport java.util.HashMap;
import java.util.Map;
import java.util.Objects;
class Emp {
int id;
String name;
// Constructor for Emp class
Emp(int id, String name) {
this.id = id;
this.name = name;
}
// Override hashCode() to generate unique hash codes based on 'id'
@Override
public int hashCode() {
// Using a prime number (31) for better distribution of hash codes
return Objects.hash(id);
}
// Override equals() to compare Emp objects based on their 'id' values
@Override
public boolean equals(Object obj) {
// If the object is the same, return true
if (this == obj) return true;
// If the object is null or not an instance of Emp, return false
if (obj == null || getClass() != obj.getClass()) return false;
// Cast the object to Emp and compare the 'id'
Emp emp = (Emp) obj;
return id == emp.id;
}
// Override toString() for better readability while printing Emp objects
@Override
public String toString() {
return "Emp{id=" + id + ", name='" + name + "'}";
}
}
public class HashMapExample {
public static void main(String[] args) {
// Create a HashMap to store Emp objects as keys with String values
Map<Emp, String> empMap = new HashMap<>();
// Create Emp objects
Emp emp1 = new Emp(1, "Nitesh");
Emp emp2 = new Emp(17, "Ajay"); // Same hashCode as emp1 due to the same id % 16
Emp emp3 = new Emp(2, "Ravi");
// Add Emp objects to the HashMap
empMap.put(emp1, "Employee 1");
empMap.put(emp2, "Employee 17");
empMap.put(emp3, "Employee 2");
// Retrieve and print values from the HashMap
System.out.println(empMap.get(emp1)); // Should print "Employee 1"
System.out.println(empMap.get(emp2)); // Should print "Employee 17"
System.out.println(empMap.get(emp3)); // Should print "Employee 2"
// Print the entire map to observe how the entries are stored
System.out.println("HashMap contents: " + empMap);
}
}
Emp Class:Emp class has two fields: id (integer) and name (String).Emp object with an id and name.hashCode():The hashCode() method is used by the HashMap to calculate the index in the internal hash table where the key-value pair will be stored. In our case, the hashCode() is overridden as follows:
@Override
public int hashCode() {
return Objects.hash(id); // Generate a hash code using the 'id' field.
}
Objects.hash(id): This is a good practice as it generates a hash code based on the id field of the Emp object. The hashCode() method helps to distribute the keys evenly across the buckets to minimize collisions. The formula id % 16 is implicitly handled by the default HashMap capacity (16), but we’ve simplified it using Objects.hash(id) for better clarity and distribution.equals():The equals() method is used to compare two Emp objects for equality, based on their id. The overridden equals() method ensures that two Emp objects with the same id are considered equal, even if they are different instances.
@Override
public boolean equals(Object obj) {
if (this == obj) return true; // Same object reference
if (obj == null || getClass() != obj.getClass()) return false; // Null or different class
Emp emp = (Emp) obj; // Cast the object to Emp
return id == emp.id; // Compare the 'id' fields for equality
}
this == obj: First, it checks if both objects are the same using reference comparison. If true, it returns true.getClass() != obj.getClass(): This checks whether the other object is of the same class (Emp).id == emp.id: Finally, it compares the id of both Emp objects to check if they are the same.toString():This method is overridden to make it easier to print out the Emp objects.
@Override
public String toString() {
return "Emp{id=" + id + ", name='" + name + "'}";
}
This ensures that when you print the Emp object, it will display its id and name fields in a readable format.
HashMap:In the main method, we create a HashMap and insert Emp objects as keys. The map stores the Emp objects with a String value. When you call empMap.get(emp1), it looks up the key using the hashCode() and equals() methods to find the correct entry.
// Adding Emp objects to the HashMap
empMap.put(emp1, "Employee 1");
empMap.put(emp2, "Employee 17");
empMap.put(emp3, "Employee 2");
// Retrieving and printing values
System.out.println(empMap.get(emp1)); // Should print "Employee 1"
System.out.println(empMap.get(emp2)); // Should print "Employee 17"
System.out.println(empMap.get(emp3)); // Should print "Employee 2"
emp1 and emp2 have different ids (1 and 17), they hash to the same bucket index (because of the hashCode() method), but they are correctly distinguished by the equals() method.In our case, both emp1 and emp2 have id values that result in the same hash code (due to id % 16), which causes a collision. The HashMap handles this collision by storing the entries in a linked list or tree structure within the same bucket. When retrieving values, it uses equals() to differentiate between the entries and returns the correct one.
The output will be as follows:
Employee 1
Employee 17
Employee 2
HashMap contents: {Emp{id=1, name='Nitesh'}=Employee 1, Emp{id=17, name='Ajay'}=Employee 17, Emp{id=2, name='Ravi'}=Employee 2}
hashCode() method ensures that keys are distributed evenly across the HashMap.equals() method ensures that two Emp objects with the same id are considered equal, even if they are different instances.HashMap will handle them using a linked list or tree, and the equals() method is used to resolve which entry to return.HashMap and How to Avoid ThemIn a HashMap, collisions occur when two or more keys generate the same hash code and thus map to the same bucket. Although hash collisions are common, especially when dealing with large sets of data, they can significantly degrade performance if not handled properly.
A collision happens when two or more distinct keys produce the same hash value, meaning they would be placed in the same bucket. For example:
hash("key1") == hash("key2")HashMapHashMap resolves collisions by storing multiple entries in the same bucket using a linked list (before Java 8) or a Red-Black Tree (after Java 8 if the bucket has more than 8 entries). However, this can cause a performance hit if the collisions are frequent because:
Use a Good Hash Function
HashMap, ensure that the hashCode() method is well-designed to generate unique hash codes for distinct objects.hashCode() properly by using multiple fields of the object and avoiding simplistic hash code implementations.Example:
@Override
public int hashCode() {
return Objects.hash(field1, field2);
}
Avoid Using Very Large Key Sets with Limited Initial Capacity
When initializing a HashMap, set the initial capacity appropriately. If your HashMap will store a large number of keys, make sure the initial capacity is large enough to avoid triggering frequent resizing and collisions.
You can set the initial capacity and load factor when creating the HashMap.
HashMap<String, Integer> map = new HashMap<>(100, 0.75f); // Initial capacity of 100
Rehashing When Collisions Occur
HashMap automatically resizes itself when the number of entries exceeds the load factor threshold, but you can control this by choosing a smaller load factor.HashMap<String, Integer> map = new HashMap<>(16, 0.5f); // Lower load factor (50%)
HashMap automatically grows when needed, but setting an optimal initial capacity can help avoid unnecessary resizing.Avoid creating keys that are too predictable or uniform.
HashMap Resolve Collisions?Before Java 8: Linked List in Buckets
HashMap stores the key-value pairs in a linked list within that bucket.Example:
// Bucket 1: [Apple -> 10, Banana -> 20] (Collision)
Java 8 and Later: Red-Black Tree in Buckets
HashMap converts the linked list into a Red-Black Tree to maintain O(log n) performance for operations like get(), put(), and remove().// Bucket 3: [Apple -> 10, Banana -> 20, Cherry -> 30, Date -> 40] (Using Red-Black Tree)
Let’s say you have a HashMap that stores employees, where the key is the employee’s ID (a string) and the value is the employee’s name.
E001, E002, E003, E004 have different hash codes, so no collision occurs, and the HashMap is efficient.E001, E002, E003), the hash codes may collide, especially if the number range is small. This would result in the keys being stored in the same bucket, affecting performance.
HashMap operations with collisions?get(), put(), and remove() operations is O(1).HashMap?HashMap automatically handles collisions through linked lists and Red-Black Trees, so manual intervention is usually not required.hashCode() method returns the same value for multiple keys?hashCode() method generates the same value for multiple keys, the HashMap will store those keys in the same bucket. The performance will degrade, and you’ll need to rely on proper collision handling (linked lists or Red-Black Trees) to maintain efficiency.
HashMap can degrade performance, but they are handled efficiently by using linked lists and Red-Black Trees.
HashMap resizes. It doubles the number of buckets and rehashes the existing entries to distribute them evenly across the new array.HashMap handle hash collisions?HashMap and TreeMap?HashMap uses hashing for storing key-value pairs and offers constant-time O(1) access on average, but with possible collisions. A TreeMap, on the other hand, uses a red-black tree structure and ensures O(log n) time complexity for all operations, but it requires the keys to be ordered.HashMap?HashMap has many collisions (i.e., many keys hash to the same bucket), performance can degrade from O(1) to O(n) for lookup, insertion, and deletion operations. Using a good hash function can help distribute keys evenly across buckets, reducing the chances of collisions.HashMap?The default initial capacity is 16 and the default load factor is 0.75. This means the map will resize when it is 75% full.
Thanks for reading HashMap Internal from Nitesh Synergy………………
Next→
LinkedHashMap is a hash table and linked list combination that maintains the insertion order (or optionally access order) of the keys. It implements the Map interface, like HashMap, but adds extra functionality to maintain the ordering of elements.
LinkedHashMap is not thread-safe by default. Like HashMap, if multiple threads access a LinkedHashMap concurrently, and at least one of them modifies the map, it should be externally synchronized (e.g., using Collections.synchronizedMap() or ConcurrentHashMap if thread safety is required).
If thread safety is a concern, you can:
Collections.synchronizedMap(new LinkedHashMap<K, V>()) to make it synchronized.ConcurrentHashMap, though it may behave slightly differently due to its concurrent access features.
Maintaining Insertion Order: If you want to keep the order in which elements were added to the map, LinkedHashMap is ideal.
Example: You are storing user session data and want to process the data in the order it was inserted.
LRU Cache Implementation: By setting it to access order, LinkedHashMap can be used for implementing a Least Recently Used (LRU) cache. The least recently accessed elements are moved to the front or back of the map, making it easy to remove them when the cache exceeds a certain size.
Example: Caching the 10 most recent items accessed from a database, where the least recently used data can be discarded when space is needed.
package com.niteshsynergy.map;
import java.util.LinkedHashMap;
import java.util.Map;
public class Demo02LinkedHashMap {
public static void main(String[] args) {
// Create a LinkedHashMap
LinkedHashMap<String, Integer> map = new LinkedHashMap<>();
// Adding elements to the LinkedHashMap
map.put("A", 1);
map.put("B", 2);
map.put("C", 3);
map.put("D", 4);
// 1. Accessing using keySet()
System.out.println("Using keySet():");
for (String key : map.keySet()) {
System.out.println(key + ": " + map.get(key));
}
// 2. Accessing using values()
System.out.println("\nUsing values():");
for (Integer value : map.values()) {
System.out.println(value);
}
// 3. Accessing using entrySet()
System.out.println("\nUsing entrySet():");
for (Map.Entry<String, Integer> entry : map.entrySet()) {
System.out.println(entry.getKey() + ": " + entry.getValue());
}
// 4. Accessing using forEach (Java 8+)
System.out.println("\nUsing forEach (Java 8+):");
map.forEach((key, value) -> System.out.println(key + ": " + value));
// Checking insertion order
System.out.println("\nInsertion Order Maintained:");
for (Map.Entry<String, Integer> entry : map.entrySet()) {
System.out.println(entry.getKey() + ": " + entry.getValue());
}
}
}
4 Ways to Access LHM
package com.niteshsynergy.map;
import java.util.LinkedHashMap;
import java.util.Map;
public class LinkedHashMapAccessExample {
public static void main(String[] args) {
// Create and populate a LinkedHashMap
LinkedHashMap<String, Integer> map = new LinkedHashMap<>();
map.put("A", 1);
map.put("B", 2);
map.put("C", 3);
// 1. Using keySet()
System.out.println("Using keySet():");
for (String key : map.keySet()) {
System.out.println(key + ": " + map.get(key));
}
// 2. Using values()
System.out.println("\nUsing values():");
for (Integer value : map.values()) {
System.out.println(value);
}
// 3. Using entrySet()
System.out.println("\nUsing entrySet():");
for (Map.Entry<String, Integer> entry : map.entrySet()) {
System.out.println(entry.getKey() + ": " + entry.getValue());
}
// 4. Using forEach() (Java 8+)
System.out.println("\nUsing forEach():");
map.forEach((key, value) -> System.out.println(key + ": " + value));
}
}



