Get in touch
Java Microservices
🔰 Phase 0 – Intro Core Foundations
🔶 What Are Microservices ?
Microservices is an architectural style where a large application is broken into small, independent services that communicate over APIs.
Each microservice:
Monolithic = A single, large codebase that handles all aspects of the system.
Problems:
🛑 Don’t use Microservices if:
Use when:
🔰 Phase 1 – Core Foundations
DDD is a strategic approach to software design that focuses on modeling software based on the core business domain, using the language, rules, and behaviors of the business itself.
It was introduced by Eric Evans in his book Domain-Driven Design: Tackling Complexity in the Heart of Software.
In microservices, design failures at the domain level lead to tight coupling across services, bloated data models, and unclear service boundaries. DDD brings clarity and alignment between the software architecture and business architecture.
A Bounded Context is a logical boundary within which a specific model is defined, understood, and maintained.
❝ One model per context; multiple models across the system. ❞
Each bounded context:
Consider an e-commerce system:
| Domain Concept | Inside Context | Ubiquitous Language | Model | Notes |
|---|---|---|---|---|
| Order | Order Management | Order, LineItem, Status | Order Aggregate | Owns the concept of order lifecycle. |
| Product | Catalog Service | Product, SKU, Price | Product Model | Defines product metadata. |
| Inventory | Warehouse Service | StockLevel, Location | Inventory Model | Tracks inventory, separate from product or order. |
| Customer | CRM Service | Customer, LoyaltyPoints | Customer Aggregate | Customer-centric operations. |
Each context:
| DDD Principle | Microservices Practice |
|---|---|
| Bounded Context | Single microservice with isolated data & logic |
| Ubiquitous Language | Clear, domain-driven APIs and payloads |
| Aggregates | Single transactional boundary (ACID scope) |
| Domain Events | Asynchronous communication (Event-driven) |
| Anti-Corruption Layer | API Gateway / Adapters / Translators to avoid leakage of other domains |
Inside each bounded context:
/orders/place, not /api/v1/saveOrder).
| Practice | Description |
|---|---|
| 🧠 Model Explicitly | Design aggregates and their invariants properly. Avoid anemic models. |
| 🚪 Explicit Boundaries | Use REST or messaging to define interfaces. Never allow leaky abstractions. |
| 🧱 Persistence Ignorance | Domain model shouldn't be tied to persistence frameworks (use ORM carefully). |
| 🧾 Event-Driven | Use domain events for integration between services, not synchronous APIs. |
| 🧪 Decentralized Governance | Teams own their bounded contexts and can deploy independently. |
| 🛡️ Anti-Corruption Layer | Translate between contexts to avoid coupling and leakage of models. |
| 🔄 Versioning | Maintain backward compatibility using schema versioning on APIs/events. |
| ⚙️ Testing the Domain | Use domain-centric testing: behavior and invariants over code coverage. |
🔷 Architecture View (Example)
+------------------+ +-----------------+ +------------------+
| Order Context |<----->| Inventory Context|<----->| Product Context |
|------------------| |------------------| |------------------|
| OrderAggregate | | StockAggregate | | ProductAggregate |
| OrderService | | InventoryService | | CatalogService |
| REST API / Events| | Events / API | | API / Events |
+------------------+ +------------------+ +------------------+
Communication:
- REST for CRUD
- Events for state changes (OrderPlaced → InventoryAdjusted)
| Feature | Monolith | Microservices |
|---|---|---|
| Deployment | Single unit | Independently deployable |
| Codebase | Unified | Distributed |
| Data Management | Centralized DB | Decentralized (Polyglot) |
| Scaling | Scale entire app | Fine-grained service scaling |
| Team Structure | Vertical teams / functional silos | Cross-functional teams aligned to business capabilities |
| DevOps | Simple | Complex (needs automation) |
| Testing | Easier E2E | Harder E2E; focus on contract & integration testing |
| Communication | In-process calls | Network calls (REST/gRPC/event-driven) |
🧠 Monoliths don’t fail because they’re monoliths. They fail when they’re poorly modularized.
| Area | Complexity |
|---|---|
| Observability | Need for tracing (Jaeger/OpenTelemetry), structured logging, metrics |
| Data Consistency | Distributed transactions → eventual consistency (Sagas, Outbox) |
| Latency | Network hops, retries, timeouts |
| Testing | Requires test doubles, mocks, contract testing (Pact) |
| Security | Each service must handle authZ/authN (JWT, mTLS, etc.) |
| DevOps | CI/CD pipelines, infrastructure-as-code, versioning, blue/green deployment |
🛠️ Rule of thumb: Only break out a service when you can own and operate it independently.
| Question | If YES |
|---|---|
| Do I have independent teams per domain? | Consider microservices |
| Do I need to scale parts of the app differently? | Consider microservices |
| Do I have mature DevOps + observability? | Consider microservices |
| Am I confident in handling distributed systems tradeoffs? | Microservices okay |
| Is the app simple, fast-moving, and team is <10 people? | Stay monolith |
| Is the domain not yet stable or clearly modeled? | Stay monolith |
🧩 Service Decomposition by Business Capabilities
At its core, this strategy aligns microservices with business capabilities, rather than technical layers or data structures.
🔑 A business capability is what the business does — a high-level, stable function such as “Order Management”, “Customer Support”, or “Payment Processing.”
Instead of carving services around:
UserController, OrderRepo, AuthService)CustomerService just for DB ops)…we define them around bounded, autonomous business areas.
| Benefit | Impact |
|---|---|
| 🔄 Independent Deployability | Each team owns a capability-aligned service |
| 🧩 Bounded Contexts | Easier to apply Domain-Driven Design |
| 🧠 Strategic Alignment | Architecture reflects how the business thinks |
| 🔒 Better Isolation | Failures and changes are localized |
| 📈 Scaling Flexibility | Scale “Checkout” differently than “Recommendation” |
| 🔁 Easier Team Structuring | Maps to Conway's Law for cross-functional teams |
Break the organization into its high-level business functions (capabilities), e.g.:
Retail Platform Capabilities:
- Customer Management
- Product Catalog
- Inventory
- Order Fulfillment
- Payment & Billing
- Shipping
- Loyalty & Rewards
Each of these becomes a candidate for a microservice boundary.
📌 Avoid premature splitting by technical layers (e.g., Auth, Logging, DB). Capabilities are holistic and vertical.
Each business capability should:
📦 Example:
Order Management, “Order” may mean a complete purchase.Inventory, “Order” may mean a stock replenishment request.Avoid tight coupling by treating them as different bounded contexts.
Each business-capability service should:
OrderPlaced, PaymentConfirmed, InventoryReservedStructure teams around business domains, not layers.
| Traditional Team | Capability-Aligned Team |
|---|---|
| Frontend Team | Product Experience Team |
| Backend Team | Catalog Service Team |
| DBA Team | Inventory Service Team |
Result: Better ownership, less coordination cost, and faster delivery.
| Capability | Responsibility |
|---|---|
| Catalog | Manage product data |
| Customer | Manage user profiles |
| Order | Handle order creation, updates |
| Inventory | Stock level, warehouse sync |
| Payment | Handle payments, refunds |
| Shipment | Manage carriers, tracking |
| Notification | Send emails, SMS |
| Loyalty | Coupons, reward points |
OrderAggregateTest)
Each capability:
| Pattern | Use When |
|---|---|
| REST API | Synchronous need (e.g., GetCustomerProfile) |
| Domain Events | Asynchronous coordination (e.g., OrderPlaced → ReserveInventory) |
| Command Bus | Directed sync commands across contexts |
| Process Orchestration (Saga) | Long-running workflows (e.g., Order → Payment → Shipment) |
| Mistake | Better Practice |
|---|---|
| Designing by technical layers | Design by business domains |
| Shared database across services | Data ownership per service |
| Premature decomposition | Start with modular monolith, extract gradually |
| Using microservices for simple apps | Microservices are a means, not a goal |
| Ignoring domain language | Use Ubiquitous Language and Bounded Contexts |
API Gateway is a single entry point for all clients, handling cross-cutting concerns and request routing.
| Responsibility | Description |
|---|---|
| 🔐 Authentication & Authorization | OAuth2, JWT, API Keys, RBAC |
| 🧱 Request Routing | Forward requests to appropriate microservices |
| 🔄 Protocol Translation | gRPC ⇄ HTTP/REST ⇄ WebSockets |
| 📦 Aggregation | Compose data from multiple services |
| 🛡️ Security | Rate limiting, throttling, IP whitelisting |
| 🧪 Observability | Tracing (Zipkin, Jaeger), Logging, Metrics |
| 🔁 Retries & Circuit Breakers | Handle transient failures (via Resilience4j, Istio) |
| 🔁 API Versioning | Route v1 vs v2 cleanly |
| 🔧 Customization per client | Mobile vs Web tailored responses |
🧰 3. Gateway Architecture
+-----------+ +------------------+
Client → | API GATEWAY| → → | Microservice A |
+-----------+ +------------------+
↓
+------------------+
| Microservice B |
+------------------+
Popular community-driven gateways with plugin support, great flexibility, and large ecosystems.
| Gateway | Key Features |
|---|---|
| Kong | Extensible via Lua plugins, supports auth, rate-limiting, logging, etc. |
| Ambassador | Kubernetes-native, gRPC & REST, built on Envoy |
| KrakenD | High-performance API aggregation, stateless, focused on composition |
| Apache APISIX | Supports dynamic routing, rate limiting, and plugins in Lua/Java |
Fully managed solutions by cloud providers. Great for teams using their ecosystem.
| Platform | Gateway | Highlights |
|---|---|---|
| AWS | API Gateway | Serverless, Swagger/OpenAPI support, throttling |
| Azure | API Management (APIM) | Developer portal, versioning, security |
| Google Cloud | Cloud Endpoints | gRPC/REST support, integrated auth, analytics |
For full control over routing logic, policies, and integration. Good for tailored microservice systems.
| Tech Stack | Use When... |
|---|---|
| Spring Cloud Gateway | Java/Spring Boot systems; integrates well with Netflix OSS, Resilience4j |
| Envoy Proxy | High-performance L7 proxy, widely used with Istio |
| Express.js + Node.js | Lightweight custom proxy, great for startup-scale or simple use cases |
| Responsibility | Description | Spring Cloud Gateway Support |
|---|---|---|
| 🔐 Authentication & Authorization | OAuth2, JWT, API Keys, RBAC | ✅ Full support via Spring Security, JWT filters, custom filters for roles |
| 🧱 Request Routing | Forward requests to appropriate microservices | ✅ Native feature using RouteLocator or application.yml |
| 🔄 Protocol Translation | gRPC ⇄ REST ⇄ WebSockets | ⚠️ Partial: WebSockets supported natively, gRPC needs proxy (e.g., Envoy or gRPC-Gateway) |
| 📦 Aggregation | Combine responses from multiple services | ✅ Possible via custom filters/controller with WebClient |
| 🛡️ Security (Rate limiting, throttling, IP blocking) | Secure APIs | ✅ Built-in RequestRateLimiter (Redis), IP filter (custom/global) |
| 🧪 Observability | Tracing, Logging, Metrics | ✅ Full support with Spring Boot Actuator, Micrometer, Zipkin, Sleuth |
| 🔁 Retries & Circuit Breakers | Handle transient errors | ✅ Full support with Resilience4j, fallback mechanisms |
| 🔁 API Versioning | Route v1, v2 APIs cleanly | ✅ Use route predicates like Path=/api/v1/** |
| 🔧 Customization per client | Web vs Mobile tailored routes | ✅ Custom filters based on headers (e.g., User-Agent) or token claims |
| Feature | REST (HTTP/JSON) | gRPC (HTTP/2 + Protobuf) |
|---|---|---|
| ✅ Simplicity | Easy to use, widely supported | Requires proto files, gRPC clients |
| 🔄 Protocol | Text-based HTTP/1.1 | Binary-based HTTP/2 |
| 📦 Payload | JSON (human-readable) | Protobuf (compact, faster) |
| 🔁 Streaming | Limited via WebSockets | Full-duplex streaming supported |
| 🧪 Tools | Postman, curl, Swagger | grpcurl, Evans, Postman (limited) |
| 📶 Performance | Slower for internal services | Highly optimized for internal traffic |
| 🔐 Auth | JWT, OAuth2 | TLS + metadata headers |
🚦 5. API Gateway + REST + gRPC – Hybrid Architecture
┌───────────────────────────────┐
│ Clients │
└───────────────────────────────┘
│
┌────────────────────┐
│ API GATEWAY │ ← REST/HTTPS
│ (Spring Cloud / Kong) │
└────────────────────┘
│ │ │
┌─────────┘ │ └────────┐
↓ ↓ ↓
+────────────+ +──────────────+ +────────────+
| Auth Svc | | Order Svc | | Catalog Svc|
+────────────+ +──────────────+ +────────────+
↓
(gRPC Internal Calls)
Spring Cloud Gateway is a reactive, non-blocking API Gateway based on Project Reactor + Spring Boot 3.
spring:
cloud:
gateway:
routes:
- id: order_service
uri: lb://ORDER-SERVICE
predicates:
- Path=/api/order/**
filters:
- StripPrefix=2
🧩 With Circuit Breaker, Retry:
filters:
- name: CircuitBreaker
args:
name: orderCB
fallbackUri: forward:/fallback/order
- name: Retry
args:
retries: 3
statuses: BAD_GATEWAY, INTERNAL_SERVER_ERROR
syntax = "proto3";
service OrderService {
rpc PlaceOrder(OrderRequest) returns (OrderResponse);
}
message OrderRequest {
string user_id = 1;
repeated string product_ids = 2;
}
🛠️ Java + gRPC Stub (Server):
public class OrderServiceImpl extends OrderServiceGrpc.OrderServiceImplBase {
public void placeOrder(OrderRequest req, StreamObserver responseObserver) {
// Business logic
}
}
Tools:
v2/order-service
filters:
- name: RequestRateLimiter
args:
redis-rate-limiter.replenishRate: 10
Combine:
| Pitfall | Remedy |
|---|---|
| Gateway becomes monolith | Keep it dumb. Delegate logic to backend services |
| Improper circuit-breaking | Use fine-grained CB policies per route |
| Aggregating too many services | Consider async responses or GraphQL |
| Lack of schema control in gRPC | Always use versioned .proto and shared repo |
| No contract testing | Use Pact or OpenAPI + CI verification |
FQA?
| Aspect | API Gateway | REST/gRPC Communication |
|---|---|---|
| ✅ Definition | A proxy layer that acts as a single entry point to your microservices ecosystem | The method/protocol used for services to communicate with each other |
| 🎯 Purpose | Manage external client communication, routing, auth, rate limiting, etc. | Enable direct service-to-service communication internally |
| 🔀 Routing | Smart routing: /api/order → order-service | Manual or via Service Discovery (Eureka, Consul, etc.) |
| 🔐 Security | Handles external security: JWT, OAuth2, WAF | Typically internal. gRPC uses mTLS; REST can be secured via mutual TLS or tokens |
| 🔧 Responsibilities | Load balancing, rate limiting, circuit breaker, API composition, caching, analytics, transformation | Serialization, transport, versioning, retry logic between services |
| 📡 Communication Scope | North-South: Client → Backend | East-West: Microservice → Microservice |
| ⚙️ Common Tech | Spring Cloud Gateway, Kong, Envoy, Zuul, AWS/GCP Gateway | REST (Spring Web, Express, FastAPI), gRPC (protobuf, grpc-java/go/etc.) |
| 🧱 Contract Style | Often OpenAPI/Swagger contracts for REST | Protobuf for gRPC; OpenAPI for REST |
| 🔄 Translation | Can convert external REST calls → internal gRPC calls | Doesn’t translate — direct |
| 🧠 Complexity | Adds infrastructure complexity, but centralizes concerns | Simpler, but spreads concerns across microservices |
| 💥 Failure Handling | Circuit breakers, timeouts, fallback strategies at entry point | Retry, failover, timeout logic coded inside service clients or with tools like Resilience4j |
| 📦 Bundling Responses | Supports response aggregation across multiple services | Point-to-point; each service handles its own part |
| 🎨 Customization | Supports Backend for Frontend (BFF) – tailor APIs per client | Typically uniform contracts and logic |
| Situation | Use API Gateway | Use REST | Use gRPC |
|---|---|---|---|
| Mobile/web clients access backend | ✅ | ✅ | ❌ |
| Internal services talk to each other | ❌ | ✅ | ✅ |
| High-throughput, low-latency required | ⚠️ (Gateway must forward fast) | ⚠️ | ✅ |
| Need streaming or multiplexing | ❌ | ❌ | ✅ |
| Simple, browser-friendly API | ✅ | ✅ | ❌ |
| Strong contracts, tight control | ✅ (with OpenAPI or proto) | ⚠️ | ✅ |
GET /api/users HTTP/1.1
Host: example.com
Authorization: Bearer token123
Content-Type: application/json
🔹 HTTP Response:
HTTP/1.1 200 OK
Content-Type: application/json
{
"id": 1,
"name": "John"
}
GET: Retrieve dataPOST: Create dataPUT: Replace dataPATCH: Modify part of dataDELETE: Delete dataOPTIONS, HEAD: Metadata or headers onlyA stateless service does not store any client session or context between requests. Each request is processed independently.
| Feature | Stateless | Stateful |
|---|---|---|
| Session | No | Yes |
| Scalability | High | Medium/Low |
| Fault Tolerance | High | Low |
| Load Balancing | Easy | Harder |
| Example | REST API | FTP Server |
GET /user/profile
Authorization: Bearer abc.def.ghi
✅ All user identity is in the token — no server-side session memory.
User ServiceAuth ServiceProduct ServicePayment ServiceEach service:
POST or PUT: make requests safe to retrySolution: Use stateless tokens (e.g., JWT) and persistent storage (DB, Redis)
Solution: Store in DB or fast stores (Redis, S3, etc.)
Each microservice owns its own database. No other service is allowed to access it directly.
❌ No shared database
✅ Full autonomy
| Benefit | Explanation |
|---|---|
| Autonomy | Each team/service evolves independently |
| Scalability | Scale only the DBs/services you need |
| Resilience | One DB crash won’t affect other services |
| Tech Freedom | One service can use MongoDB, another PostgreSQL, etc. |
| Security | No data leakage across services |
| Faster Dev | Fewer cross-team dependencies |
| Microservice | Database |
|---|---|
user-service | userdb (MySQL) |
order-service | orderdb (PostgreSQL) |
inventory-service | inventorydb (MongoDB) |
You can't do JOINs across services.
So, use event-driven or API-based patterns:
A "frontend aggregator" calls:
/user/{id}/orders?userId={id}/inventory/product/{id}Each service listens to domain events:
OrderPlaced, UserUpdated, StockUpdated✅ Loose coupling
✅ Eventually consistent
✅ Fully stateless
Bad example:
mainDBLeads to race conditions and concurrency issues
Slows everything down, introduces tight coupling
Each step:
Use:
Each service chooses DB based on its need:
| Service | Recommended DB | Reason |
|---|---|---|
User | PostgreSQL | Relational, strict constraints |
Inventory | MongoDB | Flexible schema |
Search | Elasticsearch | Text and relevance search |
Analytics | BigQuery/Redshift | High-volume analytical queries |
Payments | MySQL with ACID | Strong consistency needed |
🔄 Orchestration vs Choreography in Microservices
These two patterns define how microservices coordinate across multiple steps of a distributed business process (e.g., placing an order, reserving inventory, charging a payment, etc.).
One service (the Orchestrator) controls the workflow. It decides which service to call, in what order, and handles errors/compensation.
Think of it like a conductor leading an orchestra.
There’s no central coordinator. Services react to events and emit new ones, triggering other services to act.
Like dancers moving in sync without a choreographer—each reacts to the rhythm.
Order ServiceInventory ServicePayment ServiceShipping ServiceNotification Service
Orchestrator Service (e.g., Order Workflow Service):
CreateOrder requestInventoryService.reserveItems()PaymentService.chargeCustomer()ShippingService.scheduleDelivery()NotificationService.sendEmail()@RestController
public class OrderOrchestrator {
@PostMapping("/order")
public ResponseEntity createOrder(...) {
inventoryClient.reserve(...);
paymentClient.charge(...);
shippingClient.schedule(...);
notificationClient.send(...);
return Response.ok("Order Created");
}
}
Each service emits and listens for domain events:
OrderCreated event emittedInventoryService listens → reserves → emits InventoryReservedPaymentService listens → charges → emits PaymentSuccessfulShippingService listens → schedules → emits ShippedNotificationService listens to Shipped → sends emailEach service has only local logic. No service knows the full flow.
| Component | Orchestration | Choreography |
|---|---|---|
| Engine | Camunda, Netflix Conductor, Temporal | Kafka, RabbitMQ, NATS |
| Coordination | REST or gRPC calls | Event Bus (Pub/Sub) |
| Monitoring | Central logs in orchestrator | Distributed tracing (OpenTelemetry, Jaeger) |
| Recovery | Retry logic in orchestrator | Replayable event store |
| Compensation | Built-in in workflow engine | Listeners publish compensating events |
PaymentFailed → InventoryService listens → releaseItems()| Criteria | Use Orchestration | Use Choreography |
|---|---|---|
| Complex Workflow | ✅ | ❌ |
| Simple, reactive events | ❌ | ✅ |
| Need control/visibility | ✅ | ❌ |
| Decentralized teams | ❌ | ✅ |
| Strict rollback logic | ✅ | ❌ |
| High scalability | ❌ | ✅ |
| Auditability & observability | ✅ | ❌ |
| Feature | Implementation |
|---|---|
| Tracing | OpenTelemetry + Grafana Tempo |
| Logging | Central log aggregators (ELK/EFK) |
| Monitoring | Prometheus + Grafana |
| Event Replay | Kafka + Kafka Streams |
| Backpressure | Kafka Consumer Groups, Circuit Breakers |
| Scaling | Independent scaling of services |
| Recovery | DLQs (Dead Letter Queues) for failed events |
| Pattern | Orchestration | Choreography |
|---|---|---|
| Control | Centralized | Distributed |
| Coordination | Workflow Engine | Event Bus |
| Ease of Testing | Easier | Complex |
| Coupling | Medium | Low |
| Scaling | OK | Excellent |
| Real-world Use | Financial workflows | E-commerce, IoT, Notifications |
🧩 SAGA Pattern in Microservices
A SAGA is a sequence of local transactions in a distributed system.
Each service performs its own local transaction and emits events (or calls next steps) to continue the workflow.
If something fails, compensating transactions are invoked to undo the previous steps.
SAGA replaces distributed transactions (2PC), which don’t scale well in microservices.
Think of buying a car:
If Step 2 fails, Step 1 must be compensated (e.g., refund your money).
| Feature | Orchestration | Choreography |
|---|---|---|
| Coordination | Centralized | Decentralized |
| Control | Workflow Manager | Events |
| Compensation Logic | Inside orchestrator | Handled by individual services |
| Complexity | Easier to trace/debug | More scalable but harder to monitor |
| Common Tools | Temporal, Camunda, Netflix Conductor | Kafka, RabbitMQ, NATS |
OrderService receives CreateOrderInventoryService.reserveItems()PaymentService.charge()ShippingService.schedule()PaymentService fails → call InventoryService.cancelReservation()public class OrderOrchestrator {
public void createOrder(OrderRequest req) {
try {
inventoryClient.reserveItems(req);
paymentClient.charge(req);
shippingClient.schedule(req);
} catch (Exception e) {
// Compensating actions
paymentClient.refund(req);
inventoryClient.cancelReservation(req);
}
}
}
These help you define state machines, compensations, and timeouts cleanly.
| Area | Best Practice |
|---|---|
| Scalability | Offload orchestration to Temporal/Camunda |
| Observability | Implement distributed tracing (Jaeger/OpenTelemetry) |
| Failure Handling | Compensation should be designed with domain knowledge (e.g., refund vs reverse transaction) |
| Security | Ensure services verify source of orchestration requests |
| CI/CD | Workflow definitions should be versioned and backward-compatible |
OrderService emits OrderCreatedInventoryService listens → reserves → emits InventoryReservedPaymentService listens → charges → emits PaymentCompletedShippingService listens → schedules → emits ShippingScheduledPaymentService fails → it emits PaymentFailedInventoryService listens and rolls back reservation@KafkaListener(topics = "order.created")
public void handleOrderCreated(OrderEvent event) {
try {
reserveInventory(event);
kafkaTemplate.send("inventory.reserved", new InventoryReservedEvent(...));
} catch (Exception e) {
kafkaTemplate.send("inventory.failed", new InventoryFailedEvent(...));
}
}
| Area | Recommendation |
|---|---|
| Schema Management | Use Avro + Schema Registry |
| Compensation Logic | Event-based handlers, not tightly coupled |
| Ordering | Use Kafka partitions based on entity ID |
| Testing | Use test containers + mock event producers |
| Monitoring | Distributed tracing + log correlation IDs |
| Category | Tip |
|---|---|
| Retry Strategy | Avoid infinite retries, use exponential backoff |
| Idempotency | Ensure events and compensation are idempotent |
| Message Delivery | Use persistent brokers (Kafka) + retries |
| Transactional Outbox | Save event + DB change atomically |
| Dead Letter Queues (DLQ) | Use DLQs for failed events |
| Security | Secure the event bus, validate events |
| Audit Trail | Log every SAGA step for compliance |
Ensure data consistency when emitting events.
outbox table and emits eventAvoids issues of DB commit happening without corresponding event
| Requirement | Choose |
|---|---|
| Complex business process | Orchestration |
| Loose coupling and scale | Choreography |
| Easier debugging/tracing | Orchestration |
| Flexibility and evolution | Choreography |
| Auditability and monitoring | Orchestration (with Temporal/Camunda) |
| Feature | Temporal | Kafka |
|---|---|---|
| Flow Modeling | ✅ Visual/Code | ❌ Manual |
| Compensations | Built-in | Manual |
| Monitoring | Built-in UI | Custom needed |
| Scaling | Yes | Yes |
| Use Case | Complex Sagas | Event-based Sagas |
⚙️ CQRS + Eventual Consistency
CQRS separates read and write operations for a system.
Instead of using the same model for updates (commands) and reads (queries), it splits them into two distinct models.
Traditional CRUD:
public Product getProduct() { }
public void updateProduct(Product p) { }
Problems in Microservices:
write actions (create/update/delete)read actions (retrieval/view)In an Order Management System:
| Operation | CQRS Model |
|---|---|
| Place an Order | Command |
| Cancel Order | Command |
| Get Order Status | Query |
| List Recent Orders | Query |
CQRS usually does not update the read model synchronously.
Instead:
This causes Eventual Consistency – data syncs with delay.
| Purpose | Tools |
|---|---|
| Command/Write Model | Spring Boot, Axon, Domain Layer |
| Events | Kafka, RabbitMQ, NATS |
| Query/Read Model | MongoDB, ElasticSearch, Redis, PostgreSQL views |
| Event Handling | Axon, Debezium, Kafka Streams |
🧩 3. Microservice-Level CQRS Architecture
+-------------+ +----------------+ +---------------+
| Client |-----> | Command API |-----> | Write Service |
+-------------+ +----------------+ +---------------+
|
v
+-------------+
| Event Bus |
+-------------+
|
+--------------------------------+--------------------+
| |
+-------------------+ +------------------+
| Read Projector | | Query API |
+-------------------+ +------------------+
| |
+-------------+ +----------------+
| Read DB(s) | | Clients/UI |
+-------------+ +----------------+
POST /orders → Command APIOrderCreatedEventOrderCreatedEvent consumed by Read Projector
@PostMapping("/orders")
public ResponseEntity createOrder(@RequestBody OrderRequest req) {
Order order = orderService.createOrder(req); // Save in write DB
eventPublisher.publish(new OrderCreatedEvent(order));
return ResponseEntity.ok(order.getId());
}
✅ Event Publisher:
@Component
public class KafkaEventPublisher {
public void publish(OrderCreatedEvent event) {
kafkaTemplate.send("order.events", event);
}
}
✅ Event Handler (Read Side):
@KafkaListener(topics = "order.events")
public void handleOrderCreated(OrderCreatedEvent event) {
OrderSummary summary = new OrderSummary(event.getId(), event.getTotal(), event.getStatus());
readRepository.save(summary); // Save in ReadDB
}
| Aspect | Best Practices |
|---|---|
| Read DB | Use purpose-built projections (e.g., Redis, MongoDB, Elastic) |
| Write DB | Normalize schema for consistency |
| Event Schema | Version your events, avoid breaking changes |
| Event Handling | Ensure idempotency |
| Error Recovery | Use DLQs and retries |
| Lag Monitoring | Measure lag between write and read updates |
| Caching | Use cache for read models (with TTL) |
Avoid duplicate writes on retry:
if (!readRepository.existsByEventId(event.getEventId())) {
readRepository.save(projection);
}
Use Outbox table for reliable event publishing:
outbox table in same transaction as commandIf read side lags:
| Layer | Test |
|---|---|
| Command API | Unit + Integration |
| Events | Contract testing |
| Read Projector | Idempotency + failure |
| End-to-End | Full flow with delay simulation |
If you're building event-sourced microservices, your write DB is a log of events. You replay events to rebuild state.
OrderPlaced, ItemAdded, PaymentReceivedCan be complex, but ultra-powerful for audit/logging and temporal queries.
| Use Case | Apply CQRS |
|---|---|
| High read volume | ✅ Yes |
| Write-to-read model mismatch | ✅ Yes |
| Event-driven design | ✅ Yes |
| Simple CRUD | ❌ Overkill |
| Low latency write-to-read | ❌ Might not suit eventual consistency |
| Concept | Summary |
|---|---|
| CQRS | Split write & read models |
| Eventual Consistency | Read model lags but catches up |
| Event Bus | Connects write → read sides |
| Event Projector | Updates read DBs |
| Outbox | Guarantees delivery |
| Idempotency | Avoid duplication |
| Versioned Events | Maintain compatibility |
| Topic | Expert Tip |
|---|---|
| Schema Evolution | Never break old event contracts |
| Debugging | Trace logs with correlation IDs |
| Scaling | Separate autoscaling for read and write services |
| Observability | Add metrics for lag, throughput, replay count |
| Business Logic | Only in write side; read side is projection-only |
| Distributed Tracing | Use OpenTelemetry, Jaeger, or Zipkin |
| Partitioning | Partition read DBs by use case (geo, role, etc.) |
⚙️ Outbox Pattern & Idempotency
In event-driven microservices, when a service modifies state and publishes an event together, two things can go wrong:
| Issue | Description |
|---|---|
| Lost Events | DB is updated, but event fails to publish. |
| Inconsistent State | Event is published, but DB write fails. |
| Duplicate Events | Retry causes same event to be published multiple times. |
These violate atomicity and consistency in distributed systems.
The Outbox Pattern ensures atomicity between a service’s state change and event publication by writing both in the same database transaction.
outbox table in the same transaction.outbox table and publishes events to message broker (Kafka, RabbitMQ, etc.).
📦 3. Outbox Table Structure
CREATE TABLE outbox_event (
id UUID PRIMARY KEY,
aggregate_type VARCHAR(255),
aggregate_id VARCHAR(255),
event_type VARCHAR(255),
payload JSONB,
created_at TIMESTAMP,
published BOOLEAN DEFAULT FALSE
);
Order and OutboxEvent in same transaction.published = false rows.published = true.@Entity
@Table(name = "outbox_event")
public class OutboxEvent {
@Id private UUID id;
private String aggregateType;
private String aggregateId;
private String eventType;
@Lob @Type(JsonType.class)
private String payload;
private Instant createdAt;
private boolean published;
}
✅ Transactional Save:
@Transactional
public void createOrder(Order order) {
orderRepository.save(order);
OutboxEvent event = new OutboxEvent(
UUID.randomUUID(),
"Order",
order.getId().toString(),
"OrderCreated",
jsonMapper.write(order),
Instant.now(),
false
);
outboxRepository.save(event);
}
✅ Poller:
@Scheduled(fixedRate = 5000)
public void publishEvents() {
List events = outboxRepository.findUnpublished();
for (OutboxEvent e : events) {
kafkaTemplate.send("orders", e.getPayload());
e.setPublished(true);
outboxRepository.save(e);
}
}
| Benefit | Description |
|---|---|
| ✅ Atomicity | DB change + event written in same transaction |
| ✅ Reliability | No lost messages |
| ✅ Event replay | Events are stored & traceable |
| ✅ Auditability | Each event is persisted |
| ✅ Scalability | Independent event publishing thread/process |
Idempotency means an operation can be applied multiple times without changing the result beyond the initial application.
In microservices:
| Layer | Use |
|---|---|
| Command Handler | Avoid duplicate state transitions |
| Event Handler | Prevent duplicated projections |
| API Controller | Avoid double processing on retries |
if (dedupRepo.existsByEventId(event.getId())) return;
dedupRepo.save(new ProcessedEvent(event.getId()));
Ensure business logic ignores duplicate requests.
if (orderRepository.existsByExternalReferenceId(request.getRefId())) return;
Use database constraints to reject duplicates.
ALTER TABLE orders ADD CONSTRAINT unique_ref UNIQUE(external_reference_id);
In projection/read-side, use UPSERT instead of INSERT:
INSERT ... ON CONFLICT (id) DO UPDATE SET ...
| Pattern | Goal |
|---|---|
| Outbox | Prevent event loss and ensure async delivery |
| Idempotency | Prevent double processing from retries or duplication |
| Pitfall | Avoid It By |
|---|---|
| 🟥 Publishing inside main transaction | Always publish outside the transaction |
| 🟥 No deduplication | Always track event IDs |
| 🟥 Large outbox growth | Add TTL / archiving strategy |
| 🟥 No retries | Add retry and DLQ strategy |
| Area | Best Practice |
|---|---|
| 🧮 Event Replay | Use event versioning + replay-safe handlers |
| 🧵 Thread Separation | Run outbox processor in separate thread/process |
| 🔐 Security | Ensure sensitive data in payloads is encrypted |
| 🧰 Outbox Schema | Add sharding (e.g., partition key for Kafka) |
| ⚙️ Monitoring | Track event lag, delivery success %, and retries |
| 🔁 DLQ Handling | Store failed events with reasons and retry logic |
| 🔄 Backpressure | Use circuit breakers in poller during spikes |
| 🔄 OpenTelemetry | Trace message flow across services for observability |
Circuit Breaker, Retry, Timeout, and Bulkhead
Microservices need to maintain their responsiveness and stability under various adverse conditions: slow dependencies, outages, or network spikes. Applying resiliency patterns is critical for building robust systems.
In a typical microservice call (e.g., an Order Service calling a Payment Service):
[Client Request]
│
▼
[Order Service]
│
┌─────────────┐
│ Bulkhead │ (isolated thread pool)
└─────────────┘
│
▼
[Payment Service Call]
│ ┌────────────────────┐
├─────► │ Circuit Breaker │ (monitors error rate)
│ └────────────────────┘
│ │
Timeout/Retry logic with backoff
│ │
▼ ▼
[Payment Service Response or Fallback]
@RestController
public class PaymentController {
@Autowired
private PaymentService paymentService;
@GetMapping("/processPayment")
@CircuitBreaker(name = "paymentService", fallbackMethod = "fallbackProcessPayment")
public String processPayment() {
return paymentService.callPaymentGateway();
}
public String fallbackProcessPayment(Throwable t) {
return "Payment service unavailable. Please try again later.";
}
}
B. Retry & Timeout Example
@Service
public class PaymentService {
@Autowired
private RestTemplate restTemplate;
@Retry(name = "paymentServiceRetry", fallbackMethod = "fallbackCharge")
@TimeLimiter(name = "paymentServiceTimeout")
public CompletableFuture callPaymentGateway() {
return CompletableFuture.supplyAsync(() ->
restTemplate.getForObject("http://payment-gateway/charge", String.class));
}
public CompletableFuture fallbackCharge(Throwable t) {
return CompletableFuture.completedFuture("Payment process failed due to timeout/retries.");
}
}
@Service
public class OrderService {
@Bulkhead(name = "orderServiceBulkhead", type = Bulkhead.Type.THREADPOOL)
public String placeOrder(Order order) {
// Process the order; bulkhead ensures isolation.
return "Order placed successfully!";
}
}
Note:
The above code snippets use annotations provided by Resilience4j’s Spring Boot integration. Configuration properties in your application.yml (or properties file) define thresholds, timeout durations, and bulkhead sizes.
| Pattern | Core Idea | When to Use | Advanced Considerations |
|---|---|---|---|
| Circuit Breaker | Prevent cascading failures by tripping on errors | When calling unstable dependencies | Tune thresholds, integrate with distributed tracing, dynamic reset intervals |
| Retry | Automatically reattempt transient failures | For temporary network/time anomalies | Use exponential backoff with jitter, conditionally retry only on safe errors |
| Timeout | Limit the maximum wait time for a call | To prevent indefinite hang-ups | Adaptive timeouts based on load, granular configuration across layers |
| Bulkhead | Isolate critical resources to prevent failure bleed-over | Under high load or resource contention | Dynamically scale isolation boundaries, use separate resource pools |
deep-dive examples assignment needed.
Feature Toggles, Shadowing, and Canary Deployments
These are advanced DevOps and delivery patterns that enable safe, gradual, and observable changes in distributed systems—critical for reducing risks in microservices.
Feature Toggles allow enabling or disabling features at runtime without redeploying code.
✅ Simple Example:
if (featureFlagService.isEnabled("newCheckoutFlow")) {
useNewCheckoutFlow();
} else {
useOldCheckoutFlow();
}
| Practice | Description |
|---|---|
| Central Toggle System | Use a centralized system (e.g., LaunchDarkly, Unleash, FF4J) with audit/logging. |
| Remote Config Sync | Keep toggle states remotely configurable and cache locally to reduce latency. |
| Kill Switches | Emergency toggles for disabling services in runtime issues. |
| Toggles as Config | Separate toggle logic from business logic; treat as configuration. |
| Lifecycle Management | Retire stale toggles using automated detection tools. |
| Toggle Scope | Apply toggles at service, request, or user level granularity. |
| Observability | Toggle status should be visible in metrics and traces (Prometheus, Grafana, etc.). |
🧪 Feature Toggle with Spring Boot + FF4j:
@RestController
public class CheckoutController {
@Autowired
private FeatureManager featureManager;
@GetMapping("/checkout")
public String checkout() {
if (featureManager.isActive("NewCheckoutFeature")) {
return newCheckout();
} else {
return legacyCheckout();
}
}
}
Shadowing (a.k.a. Request Mirroring) duplicates live traffic and sends it to a new version of a service without impacting actual user experience.
| Consideration | Details |
|---|---|
| Traffic Duplication Layer | Use a gateway like Istio, Envoy, NGINX, or custom interceptors. |
| Side-by-Side Comparison | Compare logs and metrics from old vs. new service responses. |
| Data Integrity | Ensure mirrored service does not mutate data or trigger side-effects (read-only). |
| Latency Awareness | Shadowing may increase load; isolate shadow services and monitor carefully. |
| Use Cases | DB migrations, AI/ML model testing, rearchitected service trials. |
🔧 Shadowing with Envoy Example:
route:
request_mirror_policies:
- cluster: shadow-v2-service
runtime_key: mirror_enabled
Canary deployments release new versions to a small subset of users or traffic before full rollout.
| Pattern | Canary | Blue-Green |
|---|---|---|
| Gradual rollout | ✅ Yes | ❌ No (full switch) |
| Real-user feedback | ✅ Yes | ❌ No (until switched) |
| Risk control | ✅ Lower | ❌ Higher |
| Best Practice | Description |
|---|---|
| Automated Analysis | Use tools like Kayenta (Spinnaker) to auto-detect anomalies in canary metrics. |
| Health Checks | Define success/failure thresholds: latency, error rate, memory, CPU. |
| Real-Time Rollback | Automatically roll back if KPIs degrade. |
| Per-Zone Canary | Roll out to specific geographic/data center zones for deeper control. |
| Versioned APIs | Ensure backward compatibility during canary release. |
spec:
traffic:
- destination:
host: myservice
subset: v1
weight: 90
- destination:
host: myservice
subset: v2
weight: 10
spec:
traffic:
- destination:
host: myservice
subset: v1
weight: 90
- destination:
host: myservice
subset: v2
weight: 10
| Pattern | Tools |
|---|---|
| Feature Toggles | FF4j, Unleash, LaunchDarkly, ConfigCat, Spring Cloud Config |
| Shadowing | Istio, Envoy, NGINX, Linkerd |
| Canary Deployments | Argo Rollouts, Spinnaker, Flagger, Istio, AWS App Mesh |
| Pattern | Key Use Case | Risk Level | Rollback Capability | Real Traffic? |
|---|---|---|---|---|
| Feature Toggle | Runtime control of features | ✅ Low | ✅ Immediate | ✅ Yes |
| Shadowing | Pre-prod validation under load | ❌ None | N/A (read-only) | ✅ Yes (mirror) |
| Canary Deployment | Progressive rollout with monitoring | ✅ Medium | ✅ Conditional | ✅ Yes |
Spring Boot + Kubernetes demo code to implement these assigment
Event-Driven Architecture (EDA) is a reactive design style where systems communicate and operate based on events, rather than direct calls.
| Term | Definition |
|---|---|
| Event | A record that "something has happened" (e.g., OrderPlaced) |
| Event Producer | Component that emits events |
| Event Consumer | Component that listens and reacts to events |
| Event Broker | Middleware that routes events (Kafka, RabbitMQ, NATS) |
🧱 Basic Example:
1. User places an order
2. "OrderPlaced" event emitted to Kafka
3. Inventory Service consumes event → reserve stock
4. Payment Service consumes event → charge card
Rather than storing only the latest state of an entity, Event Sourcing stores a complete sequence of state-changing events.
💬 “State is derived from events, not stored directly.”
🧱 Traditional Approach:
{
"orderId": "123",
"status": "DELIVERED"
}
🔁 Event-Sourced Approach:
[
{ "event": "OrderCreated", "timestamp": "...", "data": {...} },
{ "event": "OrderConfirmed", "timestamp": "...", "data": {...} },
{ "event": "OrderShipped", "timestamp": "...", "data": {...} },
{ "event": "OrderDelivered", "timestamp": "...", "data": {...} }
]
| Aspect | Event Sourcing | Event-Driven Design (EDA) |
|---|---|---|
| Goal | Rebuild state from event history | Decouple components via asynchronous events |
| Storage | Store domain events as source of truth | Store data normally (DB + events) |
| State Model | Derived from events | Managed by each service |
| Event Type | Domain events (OrderConfirmed) | Integration events (InventoryUpdated) |
| Coupling | Tight (to domain aggregates) | Loose (event consumers are unaware of producers) |
class OrderAggregate {
private List changes = new ArrayList<>();
private OrderStatus status;
public void apply(OrderCreated event) {
this.status = OrderStatus.CREATED;
changes.add(event);
}
public List getUncommittedChanges() {
return changes;
}
}
UserRegistered, PaymentFailed, AccountLocked.v1, v2) or upcasters to handle changes in event structure.OrderCreated events to regenerate order reports.| Tool | Purpose |
|---|---|
| Apache Kafka / Redpanda | Event streaming platform |
| Debezium + CDC | Capture DB changes as events |
| Axon Framework | Java CQRS + Event Sourcing |
| EventStoreDB | Purpose-built event store |
| Kafka Streams / Flink | Real-time event processing |
| Spring Cloud Stream | Microservice event connectors |
✅ When to Use Event Sourcing?
🚫 When to Avoid?
end-to-end microservice example with Kafka, Event Sourcing, and CQRS in Java/Spring Boot assignment
🔧 Topic: Choosing the Right Message Broker in Microservices
| Component | Role |
|---|---|
| Producer | Sends (publishes) messages to a topic/queue |
| Broker | Handles routing, buffering, and delivering messages |
| Consumer | Subscribes and consumes messages from a topic/queue |
| Feature | Kafka | RabbitMQ | NATS |
|---|---|---|---|
| Protocol | TCP | AMQP 0.9.1, MQTT, STOMP | NATS (Custom, Lightweight TCP) |
| Message Retention | Persistent (log-based) | Transient by default | Memory-first (ephemeral), JetStream for persistence |
| Delivery Semantics | At least once (default) | At least once, exactly-once with plugins | At most once, at least once (JetStream) |
| Message Ordering | Partition-level ordering | No strict ordering | No strict ordering (unless JetStream) |
| Performance (throughput) | Very high (MB/s per topic) | Moderate | Extremely high (millions msg/sec) |
| Message Size | Large (MBs) | Small to medium | Small (<1MB ideal) |
| Persistence Support | Built-in log with replay | Queues persisted to disk | Optional (via JetStream) |
| Built-in Retry/Dead-letter | Yes (Kafka Streams, DLQs) | Yes | With JetStream only |
| Topology | Pub/Sub, log-streaming | Queues, Pub/Sub, Routing | Pub/Sub, Request-Reply |
| Admin Complexity | High | Medium | Very low |
| Ecosystem | Kafka Connect, Streams, Schema Registry | Shovel, Federation, Plugins | NATS Streaming, JetStream, NATS Mesh |
| Language Support | Broad | Broad | Broad |
| Use Case | Best Tool | Reason |
|---|---|---|
| Order events, audit trail | Kafka | Replayable, persisted log, partitioned scaling |
| Background job queue (e.g. email send) | RabbitMQ | Simple queue semantics with ack/retry |
| High-speed IoT telemetry | NATS | Ultra-low latency, high throughput, low footprint |
| Real-time chat, multiplayer gaming | NATS | Fast, pub-sub, request-reply support |
| Saga orchestration with retries | RabbitMQ or Kafka | Depends on need for persistence and replay |
| Bank transaction event sourcing | Kafka | Event store, guaranteed delivery, replay |
| Hybrid cloud microservice communication | NATS | Lightweight, secure, scalable |
| Criteria | Kafka | RabbitMQ | NATS |
|---|---|---|---|
| 💾 Storage Need | Event history + audit | Transient tasks | Ephemeral (unless JetStream) |
| ⚡ Speed / Latency | Good (~ms) | Moderate (~10ms) | Excellent (<1ms) |
| 📚 Message Replaying | Yes | No | JetStream only |
| 🎛 Operational Overhead | High | Medium | Very Low |
| 🔁 Retrying / DLQ | Built-in | Built-in | JetStream |
| 🛠 Tooling/Ecosystem | Excellent (Confluent) | Great (Plugins, GUIs) | Growing |
| ☁️ Cloud-native & Kubernetes | Supported (KRaft Mode) | Supported | Native + Lightweight Sidecar |
| 🧠 Developer Learning Curve | High | Medium | Low |
Use RabbitMQ or NATS for 80% of microservices. Kafka is best for streaming/data-heavy use cases.
In complex architectures, you might use Kafka for analytics/logging, RabbitMQ for job processing, and NATS for low-latency eventing.
With Kafka, enforce Avro/Protobuf + Schema Registry to avoid breaking changes.
Always design consumers to be idempotent, support retry delays, and fail gracefully.
| Scenario | Recommendation |
|---|---|
| Event sourcing, analytics | Kafka |
| Work queues, microservices comm | RabbitMQ |
| Real-time, lightweight, IoT | NATS |
| Need high durability and replay | Kafka |
| Simple job distribution | RabbitMQ |
| Low latency mesh with req-reply | NATS |
Spring Boot example that integrates Kafka or RabbitMQ or NATS with Event Sourcing + CQRS to solidify your understanding practically asignment
| Concept | Event Store | Message Broker |
|---|---|---|
| Purpose | Persist state changes as a sequence of events | Facilitate communication between services |
| Focus | Event persistence & retrieval | Event delivery & routing |
| Usage | Event Sourcing, Audit Trail, Replay | Pub/Sub, Decoupling, Async Processing |
A database optimized for append-only event persistence where every change in system state is stored as an immutable event.
A middleware that routes, buffers, and delivers messages between producer and consumer services.
| System Element | Event Store | Message Broker |
|---|---|---|
| Think of it like a... | Ledger (immutable history) | Post office (message delivery) |
| Goal | Capture what happened | Ensure who gets the message |
| Analogy | Banking transaction log | Courier service forwarding packages |
| Capability | Event Store | Message Broker |
|---|---|---|
| Data Durability | Strong (event replay) | Optional (depends on config) |
| Message Replay | Native (core design) | Possible (e.g. Kafka only) |
| Consumer Independence | Not required | Strongly required |
| Event Versioning / Schemas | Required | Optional |
| Querying / State Rebuilding | Supported | Not supported |
| Suitable for Audit Trails | Yes | No (unless persisted) |
| Stateful Projections | Yes (read model projection) | No |
| Supports Routing | No | Yes (e.g., topic/exchange-based) |
| Use in Saga/CQRS/Event Sourcing | Ideal | Sometimes (depends on persistence) |
| Partitioning / Scalability | Custom/Manual | Built-in (Kafka, NATS) |
| Use Case | Use Event Store? | Use Message Broker? |
|---|---|---|
| Audit trail of every change in order service | ✅ Yes | ❌ No (non-persistent) |
| Decouple microservices for async communication | ❌ Not suitable | ✅ Yes |
| Long-term event sourcing with replay | ✅ Yes | 🔶 Kafka only |
| Real-time notification delivery | ❌ No | ✅ Yes |
| Retrying failed message processing | ❌ No | ✅ Yes |
| Rehydrating state of a service | ✅ Yes | ❌ No |
| Fan-out updates to multiple systems | 🔶 Possible | ✅ Yes |
✅ They’re often used together in a modern architecture:
[Order Service]
|
+-------v--------+
| Save to Event Store | ← immutable record
+-------+--------+
|
[Publish Event]
↓
[Kafka/RabbitMQ Topic]
↙ ↓ ↘
Inventory Email Billing
This hybrid architecture combines:
| Factor | Event Store | Message Broker |
|---|---|---|
| Persistence | Long-term, source of truth | Optional, short-term (unless Kafka) |
| Scalability | Challenging, design-dependent | Native (Kafka/NATS scale well) |
| Complexity | Medium to High (versioning needed) | Low to Medium |
| Tooling | Limited (EventStoreDB, Axon, etc.) | Mature (Kafka, RabbitMQ, NATS) |
| Data Queries | Through projections | Not supported natively |
| Schema Evolution | Crucial | Optional |
| Replayability | Core feature | Available (Kafka), limited (others) |
| Decision Criteria | Recommended Tool |
|---|---|
| You want to track every change over time | ✅ Event Store |
| You need high-throughput real-time messaging | ✅ Kafka (Message Broker) |
| You want CQRS + Saga | ✅ Use Event Store + Broker |
| You need ordering, partitioning, scale | ✅ Kafka |
| Your services need state reconstruction | ✅ Event Store |
| Simpler async flows without sourcing | ✅ RabbitMQ or NATS |
| Stack | Use Case |
|---|---|
| EventStoreDB + Kafka | CQRS + Event Sourcing + Stream Processing |
| PostgreSQL + RabbitMQ | Transaction log + Simple async job queue |
| MongoDB + NATS JetStream | Event-logging + real-time microservices comm |
🔁 Use Message Broker for real-time communication & async orchestration.
🧾 Use Event Store to persist the truth of "what happened".
🤝 Combine both for resilient, scalable, event-driven systems.
Spring Boot + Kafka + Event Store implementation showing:assignment below included
📡 Asynchronous Communication & Message Ordering
| Synchronous Communication | Asynchronous Communication |
|---|---|
| Blocking call | Non-blocking, fire-and-forget |
| Tight coupling | Loosely coupled |
| Client waits for response | Client doesn’t wait |
| Ex: HTTP/REST | Ex: Kafka, RabbitMQ, NATS |
| Component | Description |
|---|---|
| Producer | Publishes events/messages |
| Consumer | Subscribes to and processes messages |
| Broker | Middleware (e.g., Kafka, RabbitMQ) handles delivery |
| Topics/Queues | Channels where messages are stored and routed |
| Strategy | Tools That Support It | Details |
|---|---|---|
| Kafka Partitions | Kafka | Order is preserved within a partition (use key-based partitioning) |
| Single-threaded Consumers | All brokers | Ensures one message at a time |
| FIFO Queues | AWS SQS FIFO, RabbitMQ | Guarantees ordered delivery |
| Message ID + Deduplication | App-level (custom logic) | Detect out-of-order or duplicate messages |
| Transactional Outbox | Kafka + DB with Debezium | Ensure event is produced only if DB transaction succeeds |
| Tool | Native Ordering Support | Notes |
|---|---|---|
| Kafka | Yes (per partition) | Design partitioning strategy carefully |
| RabbitMQ | Limited (depends on consumer count) | Order may be lost with multiple consumers |
| NATS | No (JetStream can be configured) | No built-in guarantees in core NATS |
| AWS SQS FIFO | Yes (strict ordering) | FIFO queues preserve exact order |
| ActiveMQ | Limited | No global order guarantee |
orderId) as Kafka partition key to ensure messages of a single entity are ordered
Topic: order-events (partitioned by orderId)
Events:
1. OrderCreated (offset: 100)
2. OrderShipped (offset: 101)
3. OrderCancelled (offset: 102)
→ Kafka ensures all of these go to the **same partition** if key = orderId
→ One consumer handles them in **exact order**
| Factor | Ordered Messaging | Unordered Messaging |
|---|---|---|
| Performance | Lower throughput | Higher throughput |
| Complexity | Higher (partition mgmt) | Lower |
| Reliability | Deterministic | Non-deterministic |
| Use Case | State transitions | Logs, Metrics, Events |
| Use Case | Need Ordering? | Broker Recommendation |
|---|---|---|
| Payment Transactions | ✅ Yes | Kafka with partitioning |
| Email Notifications | ❌ No | RabbitMQ / NATS |
| Order Lifecycle Events | ✅ Yes | Kafka / AWS FIFO SQS |
| Telemetry Data | ❌ No | NATS / Kafka (unordered) |
| Inventory Updates | ✅ Preferable | Kafka with keying |
Spring Boot Kafka project demonstrating:
customerId
From Basics to Enterprise Architecture (20+ Yrs Expertise)
A Dead Letter Queue is a failure-handling mechanism in messaging systems that stores messages that couldn’t be processed successfully, even after retries.
| Goal | Description |
|---|---|
| Isolate failures | Prevent poison messages from blocking the main queue |
| Enable retry/review | Allow manual or automated inspection |
| Audit & Compliance | Track what failed, when, and why |
| Fault-tolerance | Ensures failed messages don’t crash the whole system |
🔷 2. Basic DLQ Flow
[Producer] → [Main Queue] → [Consumer]
↳ if fail x N times
→ [DLQ]
{"userId": "123", "action": "ActivatePremium"}| Broker | DLQ Support | Notes |
|---|---|---|
| Kafka | Manual DLQ (separate topic) | Use consumer logic or Kafka Streams |
| RabbitMQ | Native DLQ via queue config | Bind DLQ via x-dead-letter-exchange |
| SQS (AWS) | Built-in DLQ config | Specify maxReceiveCount & DLQ ARN |
| NATS JetStream | Manual (Stream config) | Requeue with delay or move to fail subject |
🔷 4. Retry + DLQ Pattern (Enterprise-Ready)
[Kafka Topic]
↓
[Consumer Service] ← handles failures & retries
↓
[DLQ Topic] ← messages moved here after max retries
A replay is the reprocessing of past events/messages, usually from a DLQ, archive, or event store.
| Type | Description |
|---|---|
| Manual Replay | Admin selects messages to resend |
| Batch Replay | Reprocess a range (e.g., Kafka offset 500–600) |
| Automated Replay | DLQ triggers replay pipeline (with retry logic) |
| Event Sourcing Replay | Rebuild entire system state from event history |
| Tool | Replay Mechanism |
|---|---|
| Kafka | Consume from a specific offset or timestamp |
| RabbitMQ | Move messages from DLQ back to main queue |
| SQS | Use Lambda or batch consumer to move messages |
| Custom | Use Spring Boot Job to re-publish from DB/Outbox |
Add fields like:
{
"originalTopic": "order-events",
"originalOffset": 350,
"error": "StockNotAvailableException",
"retries": 3,
"timestamp": "2025-06-10T14:35:00Z"
}
OrderPlaced → PaymentProcessed → InventoryReserved
payment-failed-dlqpayment-topicIf you're using event sourcing, replay can be used to:
[event store] → replay → [projection updater service]
| Concept | Dead Letter Queue (DLQ) | Replay |
|---|---|---|
| Purpose | Isolate and preserve failed messages | Reprocess messages or events |
| Trigger | Max retries, processing error | Admin/manual or automated recovery |
| Implementation | Broker-configured (Rabbit/SQS) or custom | Consume from DLQ or event store |
| Key Challenges | Monitoring, alerting, storage growth | Idempotency, ordering, duplicates |
| Tools | Kafka, RabbitMQ, SQS, NATS, Spring Boot | Kafka CLI, Spring Scheduler, Cron Jobs |
Assignment:
🧠 Domain Events vs Integration Events
| Type | Description |
|---|---|
| Domain Event | An internal event that represents something that happened inside a service’s domain. |
| Integration Event | A public-facing event used to notify other microservices about changes. |
| Aspect | Domain Event | Integration Event |
|---|---|---|
| Audience | Internal (same bounded context) | External (other microservices) |
| Purpose | Capture business logic changes | Trigger inter-service communication |
| Scope | Inside the domain | Across domains / bounded contexts |
| Example | OrderConfirmedEvent in OrderService | OrderConfirmedIntegrationEvent sent to NotificationService |
OrderService// Domain Event (internal)public class OrderPlacedDomainEvent { UUID orderId; UUID customerId; LocalDateTime occurredOn;}
→ Triggers internal logic: inventory check, fraud detection.
// Integration Event (external)
public class OrderPlacedIntegrationEvent {
UUID orderId;
UUID customerId;
LocalDateTime orderDate;
}
→ Sent over Kafka/RabbitMQ → triggers email, shipment, billing microservices.
| Best Practice | Reason |
|---|---|
| Separate classes for each | Don’t expose internal models to external consumers |
| Domain Events model business rules | Encapsulate domain knowledge and invariants |
| Integration Events evolve slower | Minimize breaking changes for downstream consumers |
🔷 5. 🔁 Flow in DDD & Event-Driven Microservices
Domain Command → Domain Model → Domain Event → Local Event Handler
↳ Integration Event Published (via Outbox)
🔷 6. 🛠 Technical Handling
| Aspect | Domain Events | Integration Events |
|---|---|---|
| Transport | In-memory or local publisher | Kafka, RabbitMQ, NATS, gRPC |
| Timing | Synchronous or immediate | Asynchronous (eventual consistency) |
| Storage | No persistence needed | Often persisted via Outbox pattern |
| Failure Impact | Local service only | Can break communication across services |
| Tools | Spring Events, MediatR (C#), DDD Lib | Kafka, RabbitMQ, Debezium, Axon |
Bounded Context A
└── emits DomainEvent → converted to IntegrationEvent → published
Bounded Context B
└── listens to IntegrationEvent → triggers its own command / event
OrderConfirmedDomainEventOrderConfirmedIntegrationEventoutbox table (with transactional boundary)This guarantees:
| Concern | Expert Insight |
|---|---|
| Versioning | Integration Events need stable schemas (JSON schema/Avro) |
| Security | Never expose internal event details in integration events |
| Naming | Use domain-specific verbs (e.g., InvoiceSettled) |
| Decoupling | Domain Event → Handler → Translates to Integration Event |
| Testability | Domain events simplify unit testing of aggregate behavior |
| Observability | Integration Events should include trace IDs, timestamps, etc. |
| Feature | Domain Events | Integration Events |
|---|---|---|
| Scope | Inside service/bounded context | Cross-service / public-facing |
| Trigger | Business rule execution | Notify other services of change |
| Transport | In-memory, internal publisher | Message broker / async channel |
| Schema evolution | Rapid, private | Slow, stable, backward compatible |
| Examples | InventoryUpdatedEvent, UserDeactivated | UserDeactivatedIntegrationEvent |
| Testing Scope | Unit/integration tests | Contract + integration tests |
🧠 "Domain Events drive internal business logic. Integration Events drive communication across microservices."
Spring Boot demo showing:
💸 Distributed Transactions & Compensation
A Distributed Transaction is a transaction that spans multiple microservices or databases, requiring all of them to succeed or fail as one atomic unit.
✅ Traditional monoliths use ACID (Atomicity, Consistency, Isolation, Durability).
❌ Microservices use BASE (Basically Available, Soft state, Eventually consistent).
| Problem | Explanation |
|---|---|
| ❌ Performance overhead | Locks all resources until commit |
| ❌ Tight coupling | Services must coordinate via a centralized transaction manager |
| ❌ Scalability bottleneck | Poor fit for modern, cloud-native, horizontally scalable systems |
| ❌ Availability impact | Failing one service blocks all others |
"If you can’t rollback, then compensate."
1. Place Order ✅
2. Deduct Payment ✅
3. Reserve Inventory ✅
4. Shipping Failed ❌
→ Rollback not possible.
✅ Compensation actions:
SAGA breaks a distributed transaction into a sequence of local transactions, each followed by a compensating transaction if failure occurs.
| Step | Compensation Action |
|---|---|
| Payment Debited | Issue a refund |
| Inventory Reserved | Release the items |
| Shipment Scheduled | Cancel shipping request |
| Type | Description |
|---|---|
| Forward Recovery | Try again (retry with backoff) |
| Backward Recovery | Use compensating action to reverse the operation |
| Hybrid | Retry first, then compensate if all retries fail |
1. BookingService emits BookingCreated (outbox)
2. PaymentService listens → processes payment
3. InventoryService listens → reserves room
4. Failure? → CompensationService issues refund, cancels reservation
✅ Use Kafka topics, Outbox pattern to persist events
| Best Practice | Reason |
|---|---|
| Use Outbox + Polling Publisher | Prevent data loss when publishing events |
| Make compensations explicit & idempotent | Retry-safe and reversible logic |
| Maintain audit trails | For observability, compliance, and debugging |
| Use correlation IDs | Trace related transactions across microservices |
| Apply timeouts & retries | Handle transient failures smartly |
| Build dedicated compensation service | For clean separation of error handling |
| Tool / Lib | Use Case |
|---|---|
| Kafka | Reliable async messaging |
| Debezium + CDC | Change Data Capture for Outbox Pattern |
| Axon/SAGA DSLs | Frameworks to simplify long-running workflows |
| Spring State Machine | Manage orchestrated SAGA workflows |
[Failure Detected]
↓
[Is Operation Idempotent?] → Yes → Retry
↓ No
[Is Compensation Available?] → Yes → Execute Compensation
↓ No
→ Alert / Manual Intervention
| Feature | Distributed Transaction (XA) | Compensation Pattern |
|---|---|---|
| Atomicity | Strong (ACID) | Eventual via compensation |
| Performance | Low | High |
| Scalability | Poor | Excellent |
| Coupling | Tight | Loose |
| Failure Handling | All-or-nothing | Fine-grained rollback |
| Best for | Monolith or legacy | Microservices |
Note→ Compensating Transactions embrace the realities of distributed systems — failures, latency, and partial success — and provide business-safe reversals instead of rigid database rollbacks.
Assignment→
🚀 Phase 4 – Scalability & Load Handling in Microservices
Let’s deep dive from beginner to pro-level:
Horizontal Scaling (scale-out):
✅ Ideal for microservices because:
| Concept | Explanation |
|---|---|
| Stateless Microservices | Each service instance should not store session data |
| Shared Nothing Architecture | Each service has its own DB/cache |
| Session Storage | Offload to JWT, Redis, or DB |
| Consistent Hashing | Routes clients to specific nodes predictably |
| Service Discovery | Helps find available service instances (e.g., Eureka, Consul) |
🧱 Architecture Example
┌──────────────────┐
│ Load Balancer │
└──────┬───────────┘
↓
┌──────────────┬──────────────┐
│ Instance #1 │ Instance #2 │
│ Service A │ Service A │
└──────────────┴──────────────┘
↓
MongoDB / Kafka / Redis
| Concern | Strategy |
|---|---|
| Cold Start | Use pre-warming strategies, keep pods warm |
| Distributed Locks | Avoid where possible; use Redis/Zookeeper when needed |
| Sticky Sessions | Avoid. If required, use cookies + session store like Redis |
| Stateful Workloads | Containerize stateful apps with persistent volumes |
| Service Mesh | Automate cross-cutting concerns (Istio, Linkerd) |
| Observability | Track per-instance performance (Prometheus + Grafana + TraceId) |
| Resilience Design | Combine HPA with circuit breaker, retry, timeout, fallback |
| Tool | Use Case |
|---|---|
| Kubernetes HPA | Auto scale pods based on CPU/memory or custom metrics |
| Docker Swarm | Lightweight orchestration |
| Consul/Eureka | Service discovery |
| Spring Cloud LoadBalancer | Client-side instance selection |
| Prometheus + KEDA | Event-driven autoscaling |
| Feature | Best Practice |
|---|---|
| Stateless design | Offload state/session to Redis or JWT |
| Resilience + Observability | Add metrics, tracing, fallback, HPA |
| Scale all tiers | DBs, caches, queues, not just APIs |
| Service discovery | Automate instance awareness (Consul, Eureka) |
Assignment:
Cloud-based scalability plan (AWS/GCP/Azure)
Goal: Efficiently distribute traffic across multiple service instances to optimize performance, availability, and resilience.
| Type | Description | Example Tools |
|---|---|---|
| Client-side | The client (or SDK) holds the list of available service instances and does the balancing. | Netflix Ribbon, gRPC Client Load Balancer, Eureka |
| Server-side | A proxy, gateway, or router receives all requests and forwards them to the correct backend instance. | NGINX, Envoy, HAProxy, AWS ELB, Istio |
| Global (Geo LB) | Routes traffic across multiple data centers / regions to the nearest or healthiest location. | Azure Front Door, AWS Route 53, Cloudflare Load Balancer |
spring:
cloud:
loadbalancer:
ribbon:
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule
| Advantage | Challenge |
|---|---|
| Reduces network hops | Needs each client to handle retry/fail |
| Low latency (no proxy in path) | Discovery logic must be in every client |
| Good for internal microservices | Not ideal for public APIs |
Internet → NGINX / Envoy / AWS ALB → Microservice A (Pods)
| Benefit | Risk |
|---|---|
| Unified control point | Proxy is a potential single point of failure |
| Better observability/logging | Requires scaling proxy itself |
| Ideal for Canary/Blue-Green | Need TLS termination + rate limiting |
┌───────────────────────────────────┐
│ Global DNS Load Balancer │
│ (e.g., Route 53, Azure FrontDoor)│
└────────────────────┬──────────────┘
↓
┌──────────────────────────────────────────────────────┐
│ Server-Side Load Balancer (NGINX / Envoy / ELB) │
└──────────────┬────────────────────────────┬──────────┘
↓ ↓
Microservice A (Pod1) Microservice A (Pod2)
| Mechanism | Purpose |
|---|---|
| Retry with backoff | Handle instance failures gracefully |
| Circuit Breaker | Protect system from overload/fail-fast |
| Timeouts | Prevent long waits, ensure responsiveness |
| Failover Policy | Shift to another region or service pool |
| Metric / Log | Purpose |
|---|---|
| Request count per node | See distribution effectiveness |
| 5xx error rate | Detect overloaded or failing instances |
| Latency heatmap | Visualize slow backends |
| Health check results | Track node availability |
| Mistake | Fix |
|---|---|
| Hardcoded IPs or ports | Use service discovery with health checks |
| Ignoring locality (multi-zone issues) | Use zone-aware LB or regional sticky sessions |
| No TLS termination at proxy | Terminate TLS early (Envoy/NGINX) + mutual TLS internally |
| Monolithic API Gateway | Split into independent Edge Gateways per domain or product |
| Type | Scope | Ideal Use | Tooling Examples |
|---|---|---|---|
| Client-side | Service→Service | Internal traffic, speed | Spring Cloud LB, Ribbon, gRPC, Consul |
| Server-side | Central proxy | External traffic, security | Envoy, Istio, NGINX, HAProxy, API Gateway |
| Global | Global users | Disaster recovery, proximity | Route 53, Azure Front Door, Cloudflare |
Assignment :generate architecture diagrams / YAML setups for the load balancing layers
| Term | Definition |
|---|---|
| Rate Limiting | Restricts number of requests per unit time (e.g., 100 req/sec) |
| Throttling | Slow down or reject requests that exceed usage thresholds |
| Quota | Enforces maximum allowed usage (daily/monthly) per user/account/tenant |
| Type | Description | Example |
|---|---|---|
| Global | Across all users globally | Max 1000 rps to service |
| Per-User | Based on user identity or API key | 10 rps per user |
| Per-IP | Limits traffic from specific IPs | 100 rps per IP |
| Per-Route/Method | Different limits per endpoint | /login = 5rps, /status = 50rps |
| Time-Window Quotas | Cumulative daily/monthly limits | 1000 API calls/day |
| Burst + Steady | Allows short spikes (burst), but enforces average (steady) | Burst: 50 req, then 10 rps |
| Algorithm | Description |
|---|---|
| Fixed Window | Count requests per fixed interval (e.g., 1 min) |
| Sliding Window | More accurate by considering rolling time window |
| Token Bucket | Tokens refill at rate; requests consume them. Allows bursts. |
| Leaky Bucket | Queue incoming requests; handles traffic in steady rate |
| Concurrency Limit | Limits simultaneous inflight requests (not rate/time-based) |
# Example: Spring Cloud Gateway
spring:
cloud:
gateway:
routes:
- id: my-service
uri: http://myservice
predicates:
- Path=/api/**
filters:
- name: RequestRateLimiter
args:
redis-rate-limiter.replenishRate: 10
redis-rate-limiter.burstCapacity: 20
Apply cascading limits:
↳ Client App Plan: 1000 req/day
↳ Per IP: 100 req/min
↳ Per API Route: /login = 5 rps
For SaaS / B2B platforms:
| Plan | Daily Quota | Rate Limit (rps) |
|---|---|---|
| Free | 500 | 5 |
| Business | 10,000 | 50 |
| Enterprise | 1M | 500 |
Use JWT claims or API keys to identify plan at runtime.
| Feature | Detail |
|---|---|
| JWT Claims Based Limit | Add rate_limit field inside token |
| OAuth2 Scope Control | Define limits per scope/permission |
| API Key Throttling | Assign per-key limits at Gateway |
| Metric | Purpose |
|---|---|
| Rate limit hits | Are clients reaching limits? |
| Throttled request count | Which routes/users are being throttled? |
| Quota exhaustion | Who is using how much? |
| Average latency per user | Detect abuse or faulty clients |
| Problem | Solution |
|---|---|
| Inconsistent limits in distributed apps | Use Redis or distributed token bucket |
| Blocking the wrong users | Identify limits by account, not IP alone |
| High cost of logs/metrics for abuse | Sample metrics, log only top offenders |
| No observability | Setup alerting for limit violations |
/auth endpoint| Concept | Scope | Tools | Expert Use |
|---|---|---|---|
| Rate Limiting | rps per time unit | Redis, Gateway, Istio | Token bucket + tenant resolution |
| Throttling | soft failover | Spring filters, proxies | Dynamic scaling or fallback |
| Quota | total usage | DB, Billing systems | Monetization, SLA enforcement |
Design an API platform that supports:
Assignment:implement a Rate Limiter in Spring Boot with Redis
Used to scale databases, ensure high availability, reduce latency, and choose the right tool for each data problem.
| Concept | Definition |
|---|---|
| Partitioning | Breaking data across multiple tables or disks within the same system |
| Sharding | Distributing data across multiple databases/servers (horizontal scale) |
| Polyglot Persistence | Using multiple types of databases depending on workload |
Split data by column into different tables (e.g., separate blobs or rarely used fields).
Users(id, name, email)
UserDetails(userId, address, image)
✅ Use when: certain columns are optional, slow to query, or huge in size.
Split rows into chunks based on ID ranges or time.
Table: Orders
→ orders_2024_q1
→ orders_2024_q2
✅ Use when: you want to manage time-series or reduce I/O contention.
Sharding divides a large dataset across multiple independent databases.
| Strategy | Description | Example |
|---|---|---|
| Range-based | Split by ID or time range | Shard 1: ID 1–1000, Shard 2: 1001–2000 |
| Hash-based | Hash key (userId) % shard count | Spread evenly but hard to reshard |
| Geo-based | Split |
| Problem | Solution |
|---|---|
| Cross-shard queries | Avoid or use Query Router or CQRS |
| Resharding live traffic | Add Sharding Proxy or logical key mapping |
| Transactions across shards | Use SAGA pattern or eventual consistency |
| Product / Tech | Sharding Model |
|---|---|
| MongoDB | Built-in sharding support |
| Cassandra | Token ring partitioning |
| MySQL with Vitess | Manual / Proxy-based sharding |
| ElasticSearch | Index-level partitioning |
| YugabyteDB, CockroachDB | Auto-sharded + ACID support |
Use different types of databases for different use cases within the same system:
| Need | Recommended DB |
|---|---|
| User profiles, config | Relational (PostgreSQL, MySQL) |
| Large-scale writes / events | NoSQL (Cassandra, DynamoDB) |
| Full-text search | ElasticSearch |
| Session / Caching | Redis, Memcached |
| Time-series | InfluxDB, TimescaleDB |
| Graph data | Neo4j, JanusGraph |
| Microservice | Data Type | DB Choice | Pattern Used |
|---|---|---|---|
| User Service | Strong consistency | PostgreSQL | Vertical Partitioning |
| Cart Service | Volatile, session-like | Redis | NoSQL Cache |
| Order Service | High volume writes | Cassandra | Sharding |
| Product Search | Search + autocomplete | ElasticSearch | Index Partitioning |
| Analytics | Time series | TimescaleDB | Horizontal Partitioning |
| Feature | Tooling |
|---|---|
| Shard monitoring | Prometheus + Grafana, Datadog, Dynatrace |
| Query routing / proxy | Vitess, ProxySQL, Citus, MongoDB Router |
| Backup per shard | Custom backup jobs per physical shard |
| Data governance per store | Apache Atlas, AWS Lake Formation |
Use Case: Scalable banking platform in 5 countries
✅ Requirements:
🎯 Suggested Architecture:
| Pitfall | Fix / Advice |
|---|---|
| Cross-shard JOINs | Avoid joins across shards. Use CQRS |
| Hot shards (skewed traffic) | Use better hashing or dynamic shard rebalance |
| Backup inconsistency | Use atomic snapshotting or backup coordination |
| Wrong database for workload | Always match DB type with access pattern |
| Multiple stores = complex infra | Use shared tooling (e.g., observability, metrics, secrets) |
| Feature | Best For | Real-world Tech Examples |
|---|---|---|
| Partitioning | Managing local DBs | PostgreSQL Table Partitioning |
| Sharding | Horizontal scaling | MongoDB, Cassandra, Vitess |
| Polyglot Persistence | Domain-specific optimization | Redis, Elastic, SQL + NoSQL mix |
assignment: implementation diagrams or Spring Boot sample configs for sharded systems
📌 Pattern used to handle burst loads without overwhelming downstream systems.
Queue-Based Load Leveling introduces a message queue between fast producers (clients/microservices) and slow consumers (backends), allowing for:
Imagine a fast cashier taking orders and putting them into a queue. A slower cook processes each item from the queue at their own pace.
| Scenario | Problem | Queue-based Solution |
|---|---|---|
| High user traffic spike | DB/API crashes or becomes unresponsive | Buffer messages to process gradually |
| Third-party APIs are slow | Blocks entire microservice chain | Queue requests, retry failures later |
| Batch jobs like PDF generation | CPU load spikes | Async jobs via queue |
| Event-driven workflows | High coupling via sync calls | Loosely coupled with pub-sub |
🏗️ Architecture: Queue-Based System
Client ──> API Gateway ──> Producer Service ──> Message Queue ──> Consumer Worker ──> DB/API
→Producer: Publishes tasks/events
→ Queue: Stores buffered requests (Kafka, RabbitMQ, SQS, etc.)
→ Consumer: Listens, processes at steady rate
| Use Case | Tool Choices |
|---|---|
| Simple task queue | RabbitMQ, Amazon SQS, Azure Queue |
| High-throughput events | Apache Kafka, NATS |
| Background jobs | Celery, BullMQ, Spring @Async + MQ |
| Guaranteed delivery | Kafka (with replication), SQS FIFO |
| Complex workflows | Temporal.io, Apache Airflow, Zeebe |
If task fails, retry after delay:
retry:
maxAttempts: 5
backoff:
initialInterval: 500ms
multiplier: 2.0
Assign high-priority tasks to separate queues.
Limit consumption rate (e.g., 100msg/sec) to avoid overwhelming downstream services.
Every consumer must be idempotent:
| Metric | Action |
|---|---|
| Queue Length | Scale consumers or add more workers |
| Message Age | Detect bottlenecks |
| Processing Time | Tune task code or DB writes |
📌 Make your microservices elastic and responsive to real traffic changes.
| Term | Definition |
|---|---|
| Autoscaling | Automatically adjusting number of pods/instances based on load |
| Resource Metrics | CPU, memory, latency, queue size used to trigger scaling |
| Type | Description | Example |
|---|---|---|
| Horizontal (HPA) | Scale pod count | Add more pods if CPU > 80% |
| Vertical (VPA) | Adjust resource allocation per pod | Increase memory if under pressure |
| Cluster Autoscaler | Add/remove VM nodes | GKE, EKS, AKS auto-scale clusters |
🔧 Kubernetes HPA Example
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: my-service-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: my-service
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 75
🧠 Metrics to Use for Scaling
| Metric | Why It Matters |
|---|---|
| CPU Utilization | General compute scaling |
| Memory Usage | For in-memory workloads |
| Request Rate (rps) | Good for API microservices |
| Queue Length | Excellent for load leveling with Kafka/RMQ |
| Latency / SLA | Add more pods if response time increases |
| Custom Business Metric | Orders/sec, emails/sec |
Use ML models or traffic forecasts to scale ahead of time.
kafka-consumer-group.sh --describe --group order-consumer
llen queue_name as metric.Use warm pods or preload JVM so scaling is fast (especially for Spring Boot, Node.js).
| Tool | Purpose |
|---|---|
| Prometheus + Grafana | Metrics dashboard + alerts |
| KEDA | Event-driven autoscaler for Kubernetes |
| AWS CloudWatch | Serverless and EC2 autoscaling |
| Datadog / NewRelic | SaaS monitoring + resource graphs |
| Mistake | Why it fails |
|---|---|
| CPU-only scaling | Doesn’t handle I/O-bound services |
| Sudden scale from 0 to 100 | Cold starts can throttle response |
| Tight min-max bounds | Prevents elasticity |
| No delay buffer (scale too fast) | Cost surge, instability |
| Feature | Tooling / Pattern | Use Case Example |
|---|---|---|
| Queue-Based Load Leveling | Kafka/RabbitMQ + Worker Pods | Order processing, image jobs |
| HPA (CPU) | K8s + Prometheus | REST APIs, Spring Boot apps |
| Custom Metric Scaling | KEDA or custom controller | Email service scale by queue size |
| Predictive Scaling | ML models or historic patterns | TV apps, live sports |
Assignment:
Provide Spring Boot + RabbitMQ + HPA config samples
🧯 Phase 5 – Resilience & Failure Handling
A circuit breaker is a pattern that prevents an application from repeatedly trying a failing operation. Instead, it fails fast, avoiding cascading failures and giving the system time to recover.
| State | Description |
|---|---|
| Closed | Calls go through normally. Errors are tracked. |
| Open | Calls are blocked (fallback is triggered). After a timeout, a trial call is made. |
| Half-Open | Trial call is made. If successful, the breaker closes. If it fails, it reopens. |
| Language | Tool |
|---|---|
| Java | Resilience4j, Hystrix (legacy) |
| Node.js | opossum, cockatiel |
| Go | sony/gobreaker, resilience-go |
| Spring | @CircuitBreaker (Resilience4j/Spring Cloud Circuit Breaker) |
📌 Spring Boot Example
@CircuitBreaker(name = "inventoryService", fallbackMethod = "fallbackInventory")
public Product checkInventory(String productId) {
return inventoryClient.get(productId);
}
public Product fallbackInventory(String productId, Throwable ex) {
return new Product(productId, "Unavailable", false);
}
Inspired by ships: Isolate parts of the system to contain failures.
In microservices:
| Type | Usage |
|---|---|
| Thread-pool | Each external service has its own pool |
| Process-level | Run critical services in different containers |
| Network-level | Use sidecars or proxies (e.g., Envoy) |
The discipline of experimenting on a system to build confidence in its resilience.
| Tool | Usage |
|---|---|
| Gremlin | SaaS for controlled chaos tests |
| LitmusChaos | Kubernetes-native fault injection |
| Chaos Mesh | Open-source chaos testing framework |
| Toxiproxy | Simulates network failure, latency |
| Simmy (Polly.NET) |
Never call external services without a timeout.
Without timeouts:
| Layer | Timeout Suggestion |
|---|---|
| HTTP calls | 1–2s for downstream APIs |
| DB queries | 300ms–1s |
| Cache lookup | 100–200ms |
| Queue read/write | 500ms |
| Feature | Monitoring | Observability |
|---|---|---|
| Purpose | Alert when something goes wrong | Understand why it went wrong |
| Data | Metrics | Logs + Metrics + Traces (Three Pillars) |
| View | Static dashboard | Dynamic exploration of system behavior |
| Scenario | Strategy |
|---|---|
| One service slow | Trace latency via OpenTelemetry |
| Random 500 errors | Structured logs w/ traceId |
| Missing data | Use Kibana to correlate logs |
| Resource spike | Grafana dashboards |
| Practice | Why it Matters |
|---|---|
Always use timeout + retry + circuit breaker trio | Never leave downstream calls unprotected |
| Isolate critical services | Prevent a failure from rippling through system |
| Prefer structured JSON logging | Easier parsing, filtering |
| Use correlation IDs | Connect logs/traces across services |
| Create game day fault scenarios | Real readiness for disasters |
| Topic | Purpose | Key Tool / Practice |
|---|---|---|
| Circuit Breaker | Prevent repeated downstream failures | Resilience4j, fallback methods |
| Bulkhead | Isolate service failures | Thread pool isolation, resource limits |
| Chaos Engineering | Validate resilience through fault injection | Gremlin, Litmus, Chaos Mesh |
| Timeout Strategy | Don’t block forever | Timeouts + fail-fast + retries |
| Observability | Debug distributed failures | Logs, metrics, traces, dashboards |
🛡️ Phase 6 – Security & Governance

The small, stateless nature of microservices makes them ideal for horizontal scaling. Platforms like TAS and PKS can provide scalable infrastructure to match, with and greatly reduce your administrative overhead. Using cloud connectors, you can also consume multiple backend services with ease.
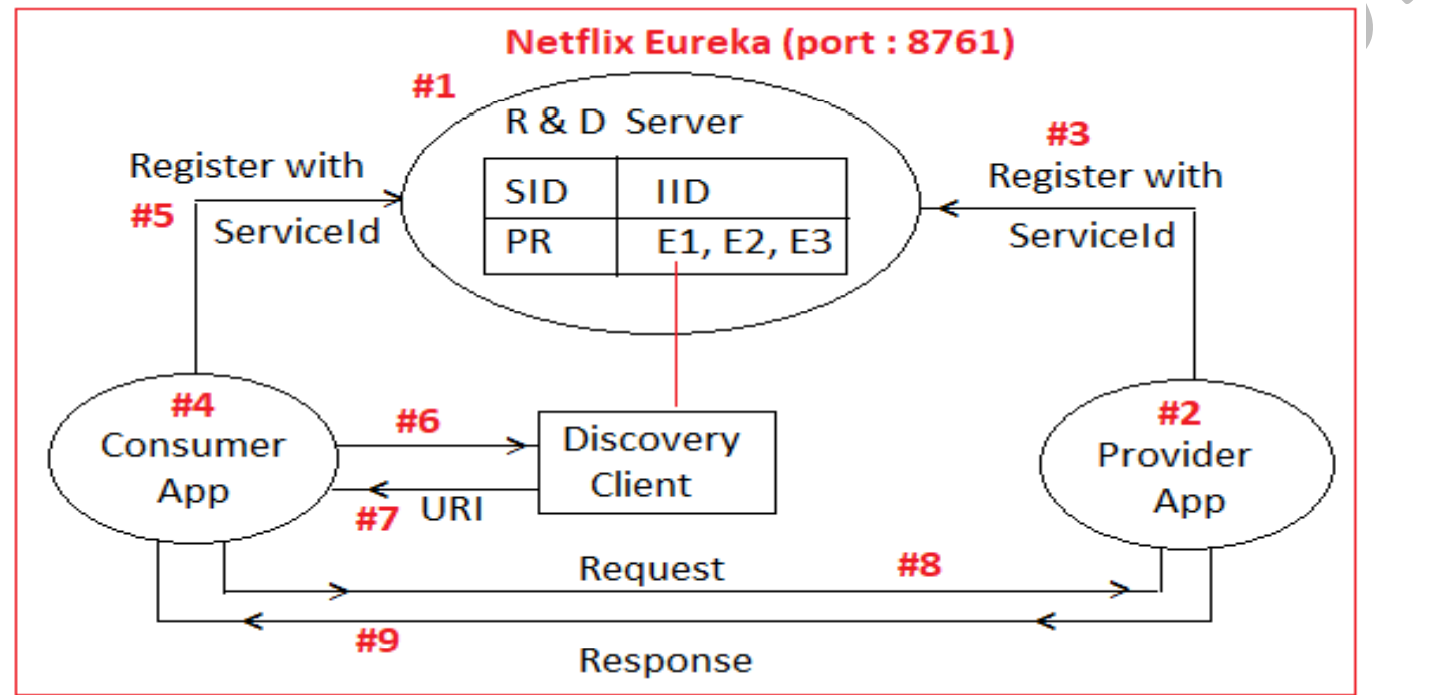
The order in which these components should typically be used or implemented while working with microservices, along with the rationale for their placement:
| Order | Component | Description | Use Case |
|---|---|---|---|
| 1 | GitHub | Stores configuration for distributed systems. | Centralized and versioned configuration management. |
| 2 | Eureka | Service registry for microservices discovery. | Enables dynamic discovery of microservices. |
| 3 | Ribbon | Client-side load balancer for service requests. | Distributes requests across multiple service instances. |
| 4 | Zuul | API Gateway for routing and pre/post filters. | Handles API routing, monitoring, and security. |
| 5 | Feign | Declarative REST client for inter-service calls. | Simplifies REST API calls between microservices. |
| 6 | OAuth2 | Secure authorization framework for servers. | Provides secure access control for APIs and users. |
| 7 | Hystrix | Provides circuit breaker pattern for resilience. | Prevents cascading failures during service downtime. |
| 8 | Kafka | Distributed message broker for event streaming. | Ensures reliable and scalable message communication. |
| 9 | Camel | Integrates and routes data between services. | Manages data flow in complex service ecosystems. |
| 10 | Actuator | Exposes production-ready monitoring endpoints. | Provides insights into service health and metrics. |
| 11 | Zipkin + Sleuth | Distributed tracing and logging for microservices. | Tracks service calls for debugging and monitoring. |
| 12 | Admin (Server/Client) | UI for real-time service monitoring and metrics. | Visualizes health and metrics of running services. |
| 13 | PCF, Docker | Platforms for cloud-based app deployment and scaling. | Simplifies app deployment and scaling in the cloud. |
Operations:--
1>Publish
2>Discover
3>Link Details of Provider
4>Query Description (Make Http Request).
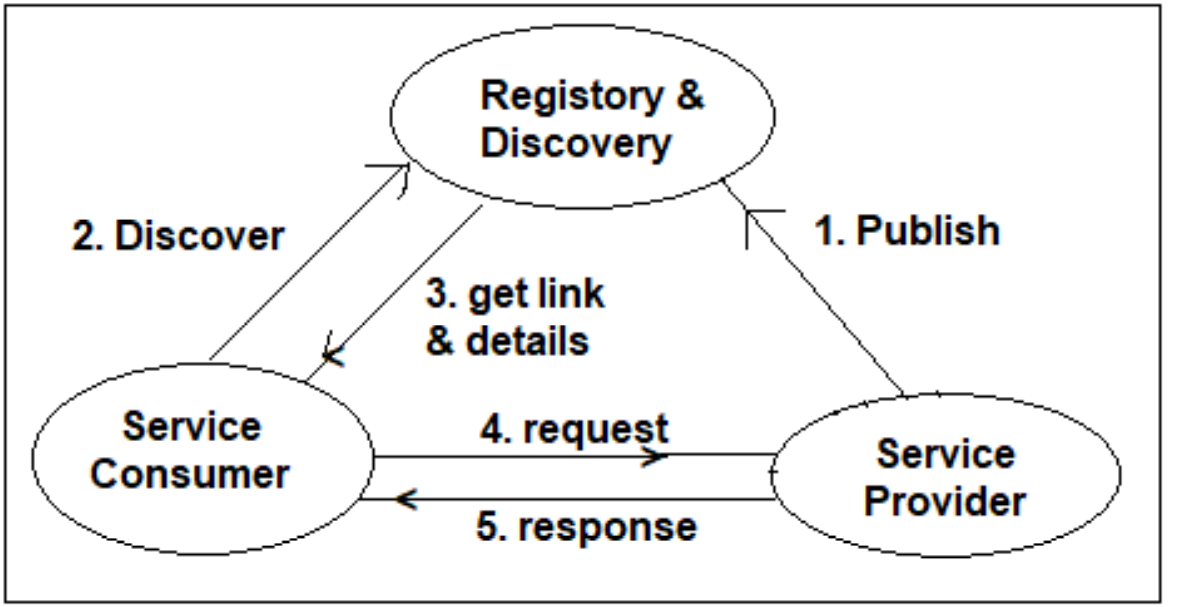
5>Access Service (Http Response).
MicroService Design and Implementation using Spring Cloud
(Netflix Eureka Registry & Discovery):--
=>Registory and Discovery server hold details of all Client (Consumer/Producer) with
its serviced and Instance Id.
=>Netflix Eureka is one R & D Server.
=>Use default port no is 8761


Your email address will not be published. Required fields are marked *



